Go容器
Go容器
数组
数组的长度不可变
var name [size]T
//声明时需要指定大小
var students [3]int
//也可以通过指针操作数组
students2 := new([3]int)
fmt.Print(*students2)
//注意初始化时,{}内的数组成员数量不能比size大
students3 := [3]int{}
students3 := [3]int{1, 2}
//或者让...根据成员的数量来确定数组的大小
students4:=[...]int{1,2,3,4}数组是一个值类型(value type)。是真真实实的数组,而不是一个指向数组内存起始位置的指针,也不能和同类型的指针进行转化,这一点严重不同于C语言。所有的值类型变量在赋值和作为参数传递时都将产生一次复制动作。如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。
func modify(arr [5]int){
arr[0] = 10
fmt.Println("In modify(), arr values:", arr)
}
func main(){
arr := [5]int{1, 2, 3, 4, 5}
modify(arr)
fmt.Println("In main(), arr values:", arr)
}输出结果为:
[root@localhost mygo]# go run test.go
In modify(), arr values: [10 2 3 4 5]
In main(), arr values: [1 2 3 4 5]slice
切片是对数组一个连续片段的引用,它是一个容量可变的序列,可以理解为动态数组。
type slice struct {
array unsafe.Pointer
len int
cap int
}(1) array是指向底层存储数据数组的指针。
(2)len指当前切片的长度,即成员数量。读写操作不能超过这个限制,不然就会panic (3) cap指当前切片的容量,它总是大于等于len。这个扩张容量也不是无限的扩张,它是受到了底层数组array的长度限制,超出了底层array的长度就会panic
从原生数组中生成切片,切片生成切片
func main() {
var arr = [...]int{0,1,2,3,4,5,6}
slice0:=arr[4:5]//cap为3
slice1 := arr[1:4] //则cap为6,len为3
slice1 := arr[1:4:5] //{low:high:max} 最多再扩张一个元素 cap为4
//max超出 len(arr)
//slice2 := arr[1:4:7] //panic
fmt.Println(slice1) //[1,2,3]
slice3 := slice1[1:3:4] //[2,3] 大于4会panic cap为3
fmt.Println(slice3)
}上面代码中创建了一个长度为7的数组arr,同时创建一个基于数组arr的切片slice1,切片引用了数组的index=1到index=3之间的元素,同时也允许切片最大扩张1个元素大小的空间。如果这个扩张空间大于7那么程序就会panic。最后创建了一个基于slice1延申的一个切片slice2,它引用了切片的index=1到index=3之间的元素,由于slice1最大扩容1个元素,因此slice2也最多扩容一个元素,超过了会panic。
创建基于底层数组的slice,其cap取值在: len<=cap<=len(arr)之间
创建基于一个切片的slice,其cap取值在: len(slice1)<=cap<=cap(slice1)之间
使用make动态创建切片
func main() {
var slice = make([]int,3,5) //len=3,cap=5
slice2 := make([]int,3,5)
fmt.Println(slice) //[0,0,0] 初值为类型的初始值
}声明新的切片
var name []T
ex :=[]int{1,2,3}//len =3 cap=3
//创建指针的时候,注意要加*号
list := new([]int)
*list = append(*list, 1)
fmt.Println(*list)向切片添加元素append
arr1:=[...]int{1,2,3,4}
arr2:=[...]int{1,2,3,4}
sli1 := arr1[0:2]//len=2,cap=4
sli2 := arr2[2:4]//len=2, cap=2
newSli1 := append(sli1,5)//arr1[1,2,5,4] newSli1[1,2,5]
newSli2 := append(sli2,5)//arr2[1,2,3,4] newSli2[3,4,5]
//切片append切片,最后需要加...
slice = append(slice,[]int{5,6,7}...)
s1 := []int{1, 2, 3}
s2 := []int{4, 5}
s1 = append(s1, s2...)
//多添加
s := make([]int, 10)
s = append(s, 1, 2, 3)1.如果容量够,直接将新元素覆盖到原有数组中,
2.如果容量不够,则需要重新申请新的底层数组,一般先申请一个大小为原来cap两倍的数组,再将之前数组的拷贝过去,再append
内建的copy函数
copy(destSli,srcSli,[]T)返回的结果为实际发生复制的元素个数,如果要保证来源切片的数据都复制到目标切片,需要保证目标切片的长度不小于来源切片的长度,否则将按照目标切片的长度进行复制。
//基本cap的增长规则
newcap := old.cap
if newcap+newcap < cap {
newcap = cap
} else {
for {
if old.len < 1024 {
newcap += newcap
} else {
newcap += newcap / 4
}
if newcap >= cap {
break
}
}改变切片里的元素
func main() {
var slice = make([]int,3,5) //len=3,cap=5
fmt.Println(slice) //[0,0,0]
slice2:=slice[:5] //slice实现了对slice的扩容,切片长度变为5
fmt.Println(slice2) //[0,0,0,0,0]
slice[0] = 999 //这里slice和slice的index=0位置都是999 因为他们引用的底层数组的index=0位置都是999
fmt.Println(slice)
fmt.Println(slice2)
AddOne(slice) //[8888,0,0]
fmt.Println(slice) //[8888,0,0]
fmt.Println(slice2) //[8888,0,0,0]
}
func AddOne(s []int){
s[0] = 8888
fmt.Println(s)
}slice作为函数参数需要注意
func testSli(sli []int) {
sli = append(sli, 777)
fmt.Println(sli)
}
func main() {
// arry := [3]int{1, 2, 3}
// testArr(arry)
// fmt.Println(arry)
sli1 := make([]int, 3, 5)
testSli(sli1)
fmt.Println(sli1)
sli2 := sli1[0:5]
fmt.Println(sli2)
}输出结果:
[0 0 0 777]
[0 0 0]
[0 0 0 777 0]可以理解为,slice作为函数参数传递也是值传递,但由于slice是一个结构体,里面有一个数组的指针,所以append会修改数组里的内容,但是作为值传递,无法修改len,cap的值。所以在外部看到的还是原来的slice,len都没有改变,但是用一个新的slice2去遍历可以看到数组里的内容确实发生了变化。
如果发生了扩容出现的情况:
func testSli2(sli []int) {
sli = append(sli, 2, 2, 2, 2, 2, 2)
fmt.Println(sli)
}
func main(){
sli3 := make([]int, 0, 3)
testSli2(sli3)
fmt.Println(sli3)
sli4 := sli3[0:3]
fmt.Println(sli4)
}输出结果:
[2 2 2 2 2 2]
[]
[0 0 0]可以这么理解,由于sli3的cap为3,当append需要扩容的时候,改变了数组指针的值,但这个改变只在test内部函数可以见,无法对原来的sli2进行修改,所以当sli4遍历sli3的时候,发现sli2并没有append 2进去。
如果容量不够,则需要重新申请新的底层数组,一般先申请一个新数组,再将之前数组的拷贝过去,再append
test2改变的是一个新扩容数组,对原数组并没有变化,然后再将sli2的指针指向了这个新数组。但是值传递,是对原来sli2的拷贝,并不会影响原来的sli2。
如果append不扩容的话,sli2的指针不会变化,可以看到底层数组发生了变化,但是原来sli的len不会改变(值传递)
map
Go语言中 map 是一种特殊的数据结构,一种元素对(pair)的无序集合,pair 对应一个 key(索引)和一个 value(值),所以这个结构也称为关联数组或字典,这是一种能够快速寻找值的理想结构,给定 key,就可以迅速找到对应的 value。
初始化
map1 := make(map[int]string)
//map1 := make(map[int]string)等价于 map1 :=map[int]string{}。
var map2 map[int]string//这样还不能使用,因为他没有分配内存
//可以指定容量
make(map[keytype]valuetype, cap)
//切片作为map的值
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 pair 的数目。
底层实现
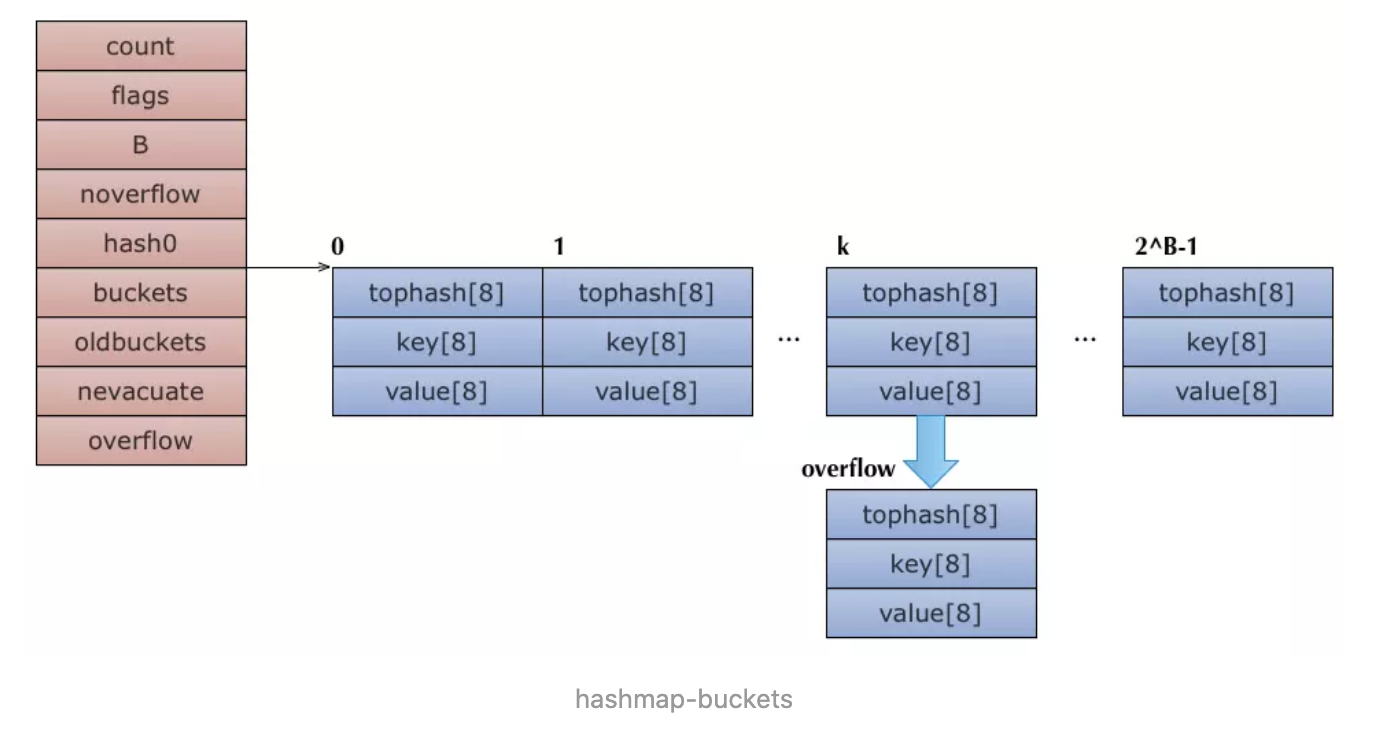
//map结构体是hmap,是hashmap的缩写
type hmap struct {
count int //元素个数,调用len(map)时直接返回
flags uint8 //标志map当前状态,正在删除元素、添加元素.....
B uint8 //单元(buckets)的对数 B=5表示能容纳32个元素
noverflow uint16 //单元(buckets)溢出数量,如果一个单元能存8个key,此时存储了9个,溢出了,就需要再增加一个单元
hash0 uint32 //哈希种子
buckets unsafe.Pointer //指向单元(buckets)数组,大小为2^B,可以为nil
oldbuckets unsafe.Pointer //扩容的时候,buckets长度会是oldbuckets的两倍
nevacute uintptr //指示扩容进度,小于此buckets迁移完成
extra *mapextra //与gc相关 可选字段
}
//a bucket for a Go map
type bmap struct {
// 每个元素hash值的高8位,如果tophash[0] < minTopHash,表示这个桶的搬迁状态
tophash [bucketCnt]uint8
// 接下来是8个key、8个value,但是我们不能直接看到;为了优化对齐,go采用了key放在一起,value放在一起的存储方式,
// 再接下来是hash冲突发生时,下一个溢出桶的地址
}
//实际上编辑期间会动态生成一个新的结构体
type bmap struct {
topbits [8]uint8 //存8个高8位hash
keys [8]keytype //存8个key
values [8]valuetype//8个value
pad uintptr //pading
overflow uintptr //指向下一个溢出桶
} Go的map就是hashmap,源码在src/runtime/hashmap.go。对比C++用红黑树实现的map,Go的map是unordered map,即无法对key值排序遍历。跟传统的hashmap的实现方法一样,它通过一个buckets数组实现,所有元素被hash到数组的bucket中,buckets就是指向了这个内存连续分配的数组。B字段说明hash表大小是2的指数,即2^B。每次扩容会增加到上次大小的两倍,即2^(B+1)。当bucket填满后,将通过overflow指针来mallocgc一个bucket出来形成链表,也就是为哈希表解决冲突问题。
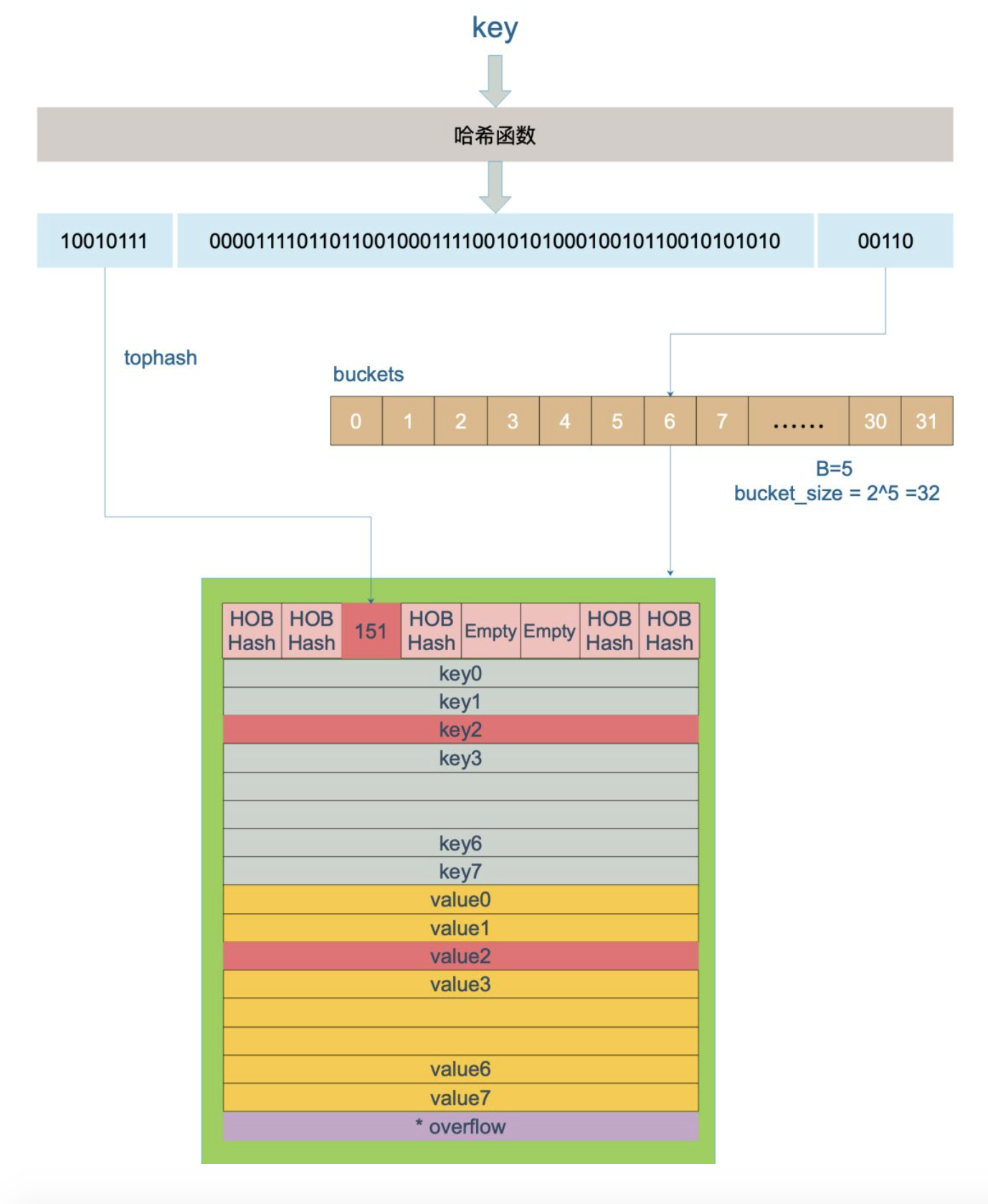
计算hash
| key | hash | hashtop | bucket index |
|---|---|---|---|
| key | hash := alg.hash(key, uintptr(h.hash0)) | top := uint8(hash >> (sys.PtrSize*8 - 8)) | bucket := hash & (uintptr(1)<<h.B - 1),即 hash % 2^B |
例如,对于B = 3,当hash(key) = 4时, hashtop = 0, bucket = 4,当hash(key) = 20时,hashtop = 0, bucket = 4;
每个key落在桶的位置由hash出来的结果的高8位决定,链表在数组中的位置是由低位决定的,hash % 2^B,结果刚好是数组的长度。
key经过哈希值计算得到哈希值,共64位(64位机器),后面5位用于计算该key放在哪一个bucket中,前8位用于确定该key在bucket中的位置;比如一个key经过计算结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 0101001010值是10,也就是第10个bucket;10010111值是151,在6号bucket中查找tophash值为151的key(最开始bucket还没有 key,新加入的 key 会找到第一个空位,放入)。
遍历查找
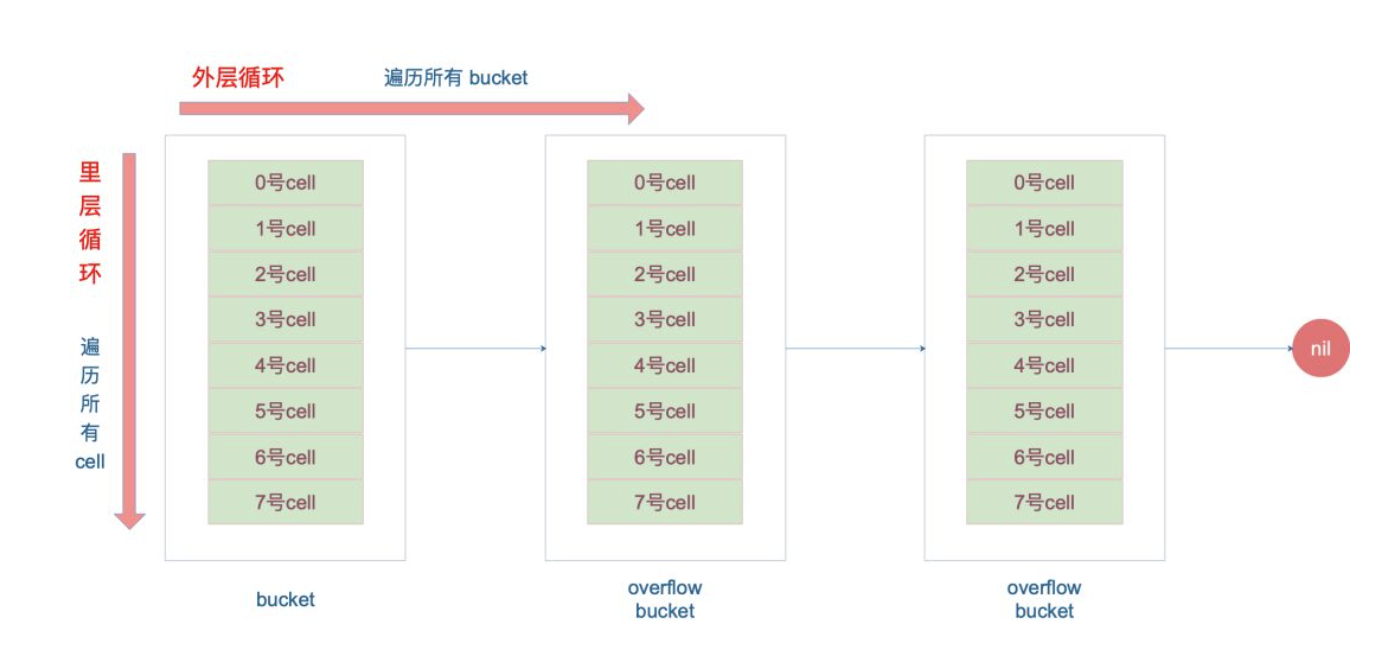
里说一下定位key和value的方法以及整个循环的写法:
//key定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//value定位公式
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))b是bmap的地址,dataOffset是key相对于bmap起始地址的偏移:
dataOffset=unsafe.Offsetof(struct{
b bmap
v int64
}{}.v)因此bucket里key的起始地址就是unsafe.Pointer(b)+dataOffset;第i个key的地址就要此基础上加i个key大小;value的地址是在key之后,所以第i个value,要加上所有的key的偏移。
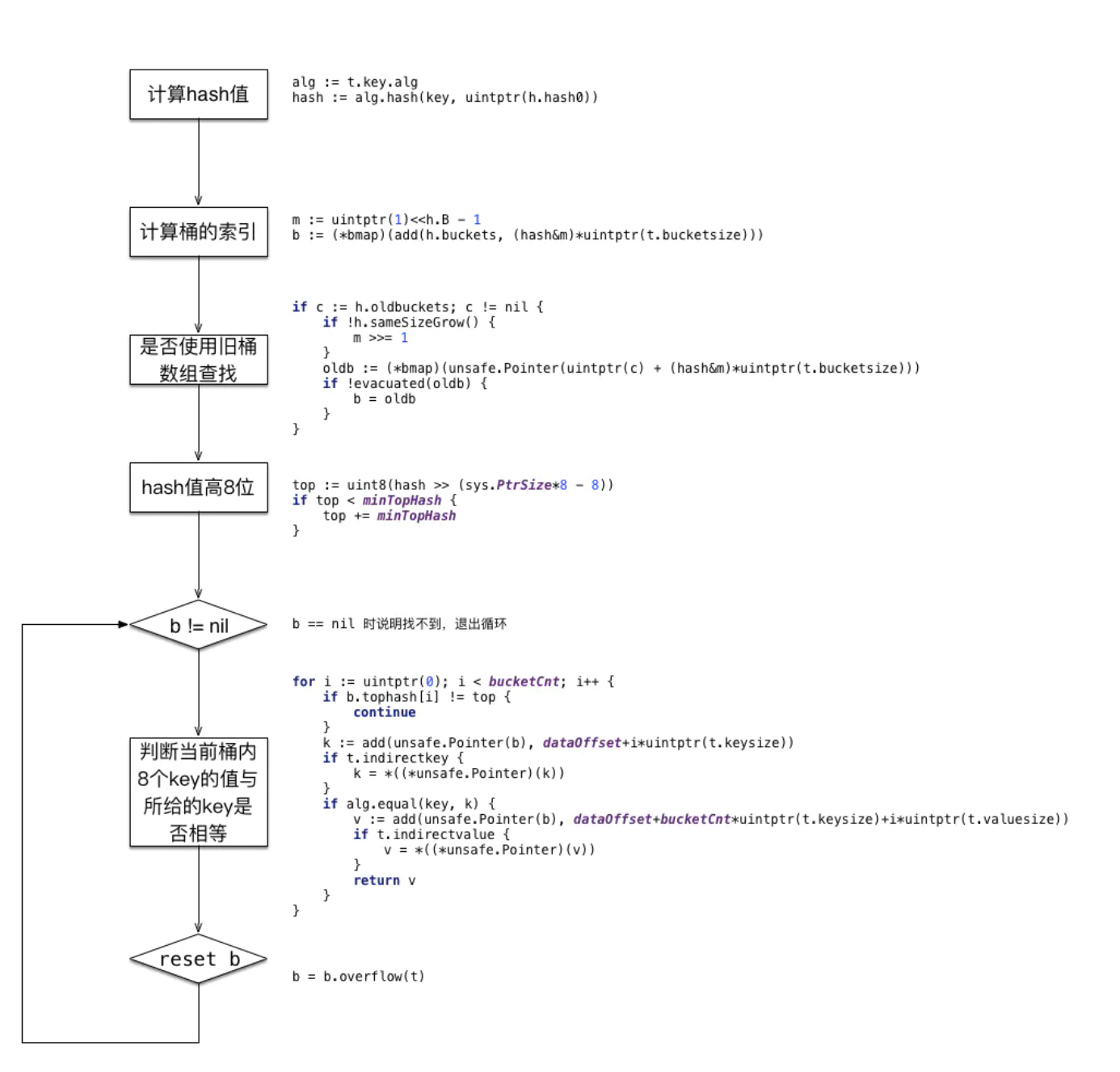
从源码中可以看到,先根据hash的低位找到桶的索引,之后计算高位的hash,去与一个桶中的tophash比较,只有高位hash相等了,才继续比较key。如果一个桶中比较完了,没找到,但还有overflow,则将b指向他的溢出桶。
/ mapaccess1返回一个指向h[键]的指针。决不返回nil,相反,如果键不在映射中,它将返回对elem类型的zero对象的引用。
// 注意:返回的指针可能会使整个映射保持活动状态,所以不要长时间保持。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
//如果h说明都没有,返回零值
if h == nil || h.count == 0 {
if t.hashMightPanic() { //如果哈希函数出错
t.key.alg.hash(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
//写和读冲突
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
//不同类型的key需要不同的hash算法需要在编译期间确定
alg := t.key.alg
//利用hash0引入随机性,计算哈希值
hash := alg.hash(key, uintptr(h.hash0))
//比如B=5那m就是31二进制是全1,
//求bucket num时,将hash与m相与,
//达到bucket num由hash的低8位决定的效果,
//bucketMask函数掩蔽了移位量,省略了溢出检查。
m := bucketMask(h.B)
//b即bucket的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不为 nil,说明发生了扩容
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
//新的bucket是旧的bucket两倍
m >>= 1
}
//求出key在旧的bucket中的位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
//如果旧的bucket还没有搬迁到新的bucket中,那就在老的bucket中寻找
if !evacuated(oldb) {
b = oldb
}
}
//计算tophash高8位
top := tophash(hash)
bucketloop:
//遍历所有overflow里面的bucket
for ; b != nil; b = b.overflow(t) {
//遍历8个bucket
for i := uintptr(0); i < bucketCnt; i++ {
//tophash不匹配,继续
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//tophash匹配,定位到key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//若key为指针
if t.indirectkey() {
//解引用
k = *((*unsafe.Pointer)(k))
}
//key相等
if alg.equal(key, k) {
//定位value的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
//value解引用
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
//没有找到,返回0值
return unsafe.Pointer(&zeroVal[0])
}插入存值 mapassign
首先用key的hash值低8位找到bucket,然后在bucket内部比对tophash和高8位与其对应的key值与入参key是否相等,注意,比完hash值的高8位还需比较key值是否相等,若找到则更新这个值。若key不存在,则key优先存入在查找的过程中遇到的空的tophash数组位置。若当前的bucket已满则需要另外分配空间给这个key,新分配的bucket将挂在overflow链表后。
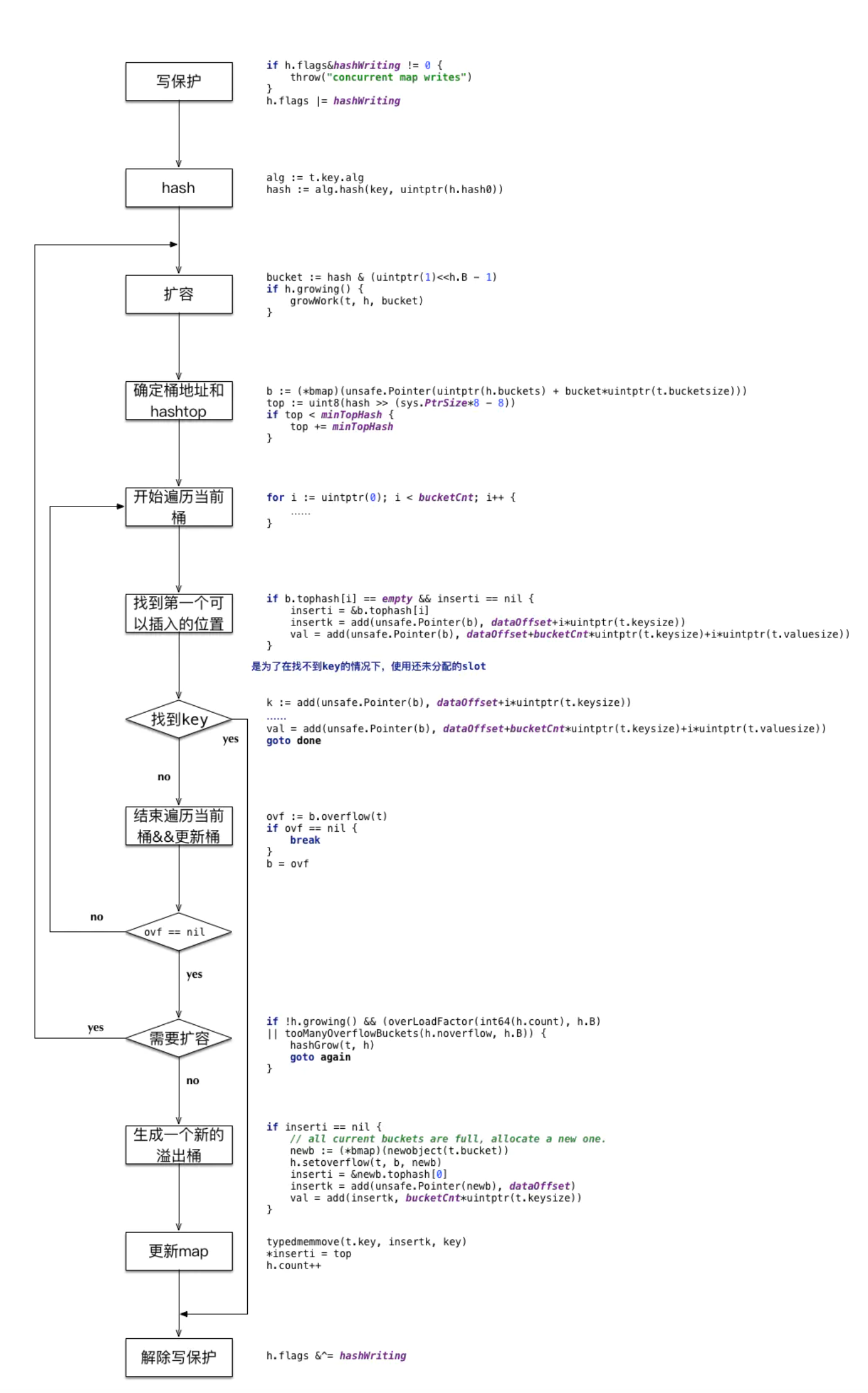
那么当 key 定位到了某个 bucket 后,需要确保这个 bucket 对应的老 bucket 完成了迁移过程。即老 bucket 里的 key 都要迁移到新的 bucket 中来(分裂到 2 个新 bucket),才能在新的 bucket 中进行插入或者更新的操作。
上面说的操作是在函数靠前的位置进行的,只有进行完了这个搬迁操作后,我们才能放心地在新 bucket 里定位 key 要安置的地址,再进行之后的操作。
func mapassign1(t *maptype, h *hmap, key unsafe.Pointer, val unsafe.Pointer) {
hash := alg.hash(key, uintptr(h.hash0))
if h.buckets == nil {
h.buckets = newarray(t.bucket, 1)
}
again:
//根据低8位hash值找到对应的buckets
bucket := hash & ( uintptr( 1)<<h.B - 1)
b := (bmap)(unsafe.Pointer( uintptr(h.buckets) + bucketuintptr(t.bucketsize)))
//计算hash值的高8位
top := uint8(hash >> (sys.PtrSize* 8 - 8))
for {
//遍历每一个bucket 对比所有tophash是否与top相等
//若找到空tophash位置则标记为可插入位置
for i := uintptr( 0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == empty && inserti == nil {
inserti = &b.tophash[i]
}
continue
}
//当前tophash对应的key位置可以根据bucket的偏移量找到
k2 := add(unsafe.Pointer(b), dataOffset+i* uintptr(t.keysize))
if !alg.equal(key, k2) {
continue
}
//找到符合tophash对应的key位置
typedmemmove(t.elem, v2, val)
goto done
}
//若overflow为空则break
ovf := b.overflow(t)
}
// did not find mapping for key. Allocate new cell & add entry.
if float32(h.count) >= loadFactor* float32(( uintptr( 1)<<h.B)) && h.count >= bucketCnt {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// all current buckets are full, allocate a new one.
if inserti == nil {
newb := (*bmap)(newobject(t.bucket))
h.setoverflow(t, b, newb)
inserti = &newb.tophash[ 0]
}
// store new key/value at insert position
kmem := newobject(t.key)
vmem := newobject(t.elem)
typedmemmove(t.key, insertk, key)
typedmemmove(t.elem, insertv, val)
*inserti = top
h.count++
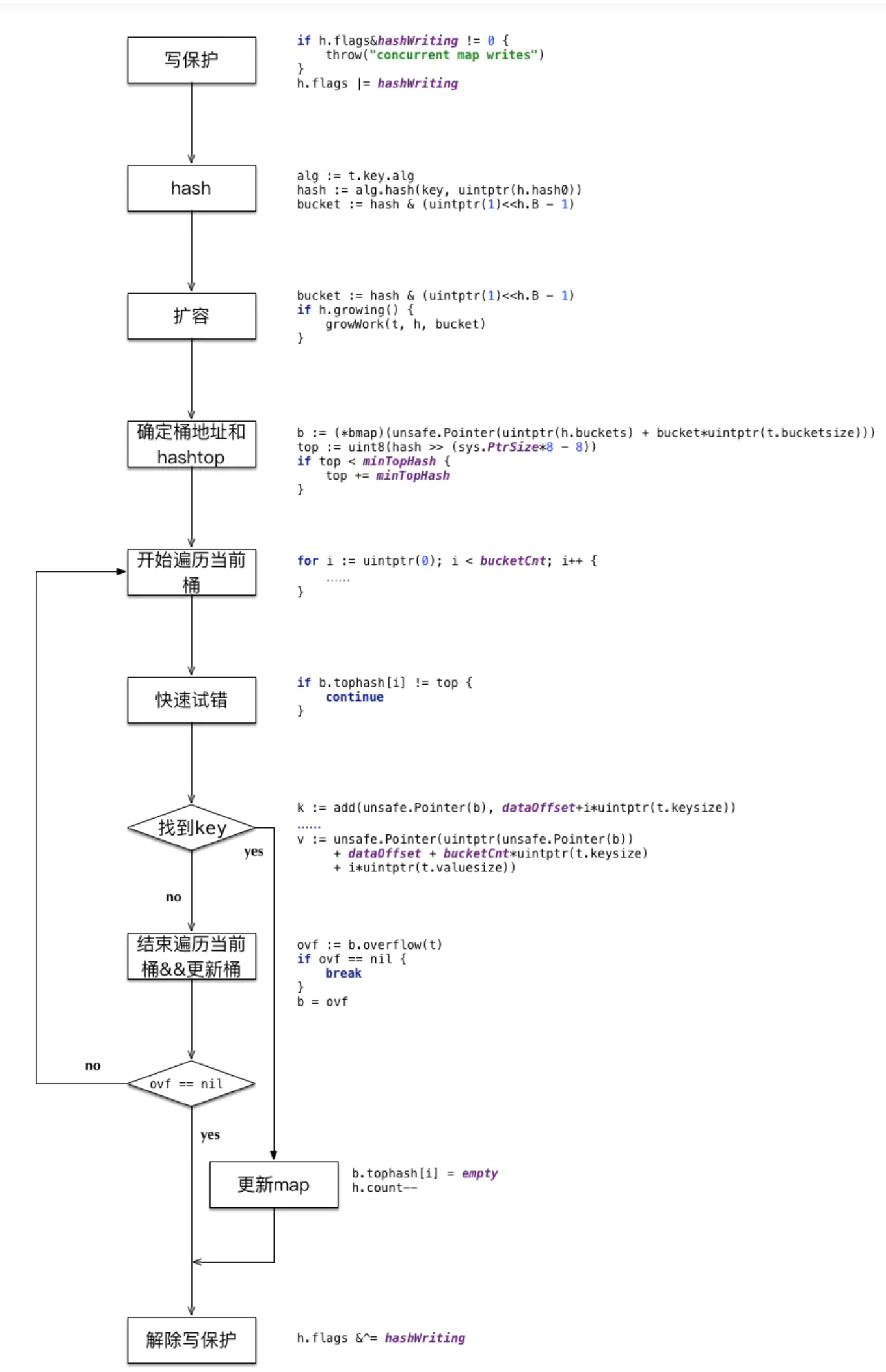
}删除 mapdelete
删除某个key的操作与分配类似,由于hashmap的存储结构是数组+链表,所以真正删除key仅仅是将对应的slot设置为empty,并没有减少内存;如下:
扩容
map 扩容的时机:在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容:
- 装载因子超过阈值,源码里定义的阈值是 6.5。
- overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。
第 1 点:我们知道,每个 bucket 有 8 个空位,在没有溢出,且所有的桶都装满了的情况下,装载因子算出来的结果是 8。因此当装载因子超过 6.5 时,表明很多 bucket 都快要装满了,查找效率和插入效率都变低了。在这个时候进行扩容是有必要的。
第 2 点:是对第 1 点的补充。就是说在装载因子比较小的情况下,这时候 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。表面现象就是计算装载因子的分子比较小,即 map 里元素总数少,但是 bucket 数量多(真实分配的 bucket 数量多,包括大量的 overflow bucket)。
不难想像造成这种情况的原因:不停地插入、删除元素。先插入很多元素,导致创建了很多 bucket,但是装载因子达不到第 1 点的临界值,未触发扩容来缓解这种情况。之后,删除元素降低元素总数量,再插入很多元素,导致创建很多的 overflow bucket,但就是不会触犯第 1 点的规定,你能拿我怎么办?overflow bucket 数量太多,导致 key 会很分散,查找插入效率低得吓人,因此出台第 2 点规定。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
对于条件 1,元素太多,而 bucket 数量太少,很简单:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。于是,就有新老 bucket 了。注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来。而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)。
对于条件 2,其实元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
首先,判断是否需要扩容的逻辑是
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}oldbuckets不为空,说明还没有搬迁完毕,还得继续搬。
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果有大量的 key/value 需要搬迁,会非常影响性能。因此 Go map 的扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。
hashGrow()函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。真正搬迁 buckets 的动作在 growWork()函数中,而调用 growWork()函数的动作是在 mapassign 和 mapdelete 函数中。也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil。也就是说在插入和删除前,会判断老桶是否已经迁移到新桶中,还没迁移先迁移,迁移完成再进行插入和删除。
在分配assign逻辑中,当没有位置给key使用,而且满足测试条件(装载因子>6.5或有太多溢出桶)时,会触发hashGrow逻辑:
func hashGrow(t *maptype, h *hmap) {
//判断是否需要sameSizeGrow,否则"真"扩
// B+1 相当于是原来 2 倍的空间
bigger := uint8(1)
// 对应条件 2
if !overLoadFactor(int64(h.count), h.B) {
// 进行等量的内存扩容,所以 B 不变
bigger = 0
h.flags |= sameSizeGrow
}
// 下面将buckets复制给oldbuckets
oldbuckets := h.buckets
//申请新的 buckets 空间
newbuckets := newarray(t.bucket, 1<<(h.B+bigger))
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 更新hmap的变量
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 搬迁进度为 0
h.nevacuate = 0
h.noverflow = 0
// 设置溢出桶
if h.overflow != nil {
if h.overflow[1] != nil {
throw("overflow is not nil")
}
// 交换溢出桶
h.overflow[1] = h.overflow[0]
h.overflow[0] = nil
}
}真正执行搬迁工作的 growWork() 函数。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 确认搬迁老的 bucket 对应正在使用的 bucket
evacuate(t, h, bucket&h.oldbucketmask())
// 再搬迁一个 bucket,以加快搬迁进程
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}搬迁的关键函数 evacuate
evacuate 函数每次只完成一个 bucket 的搬迁工作,因此要遍历完此 bucket 的所有的 cell,将有值的 cell copy 到新的地方。bucket 还会链接 overflow bucket,它们同样需要搬迁。因此会有 2 层循环,外层遍历 bucket 和 overflow bucket,内层遍历 bucket 的所有 cell。
迁移过程

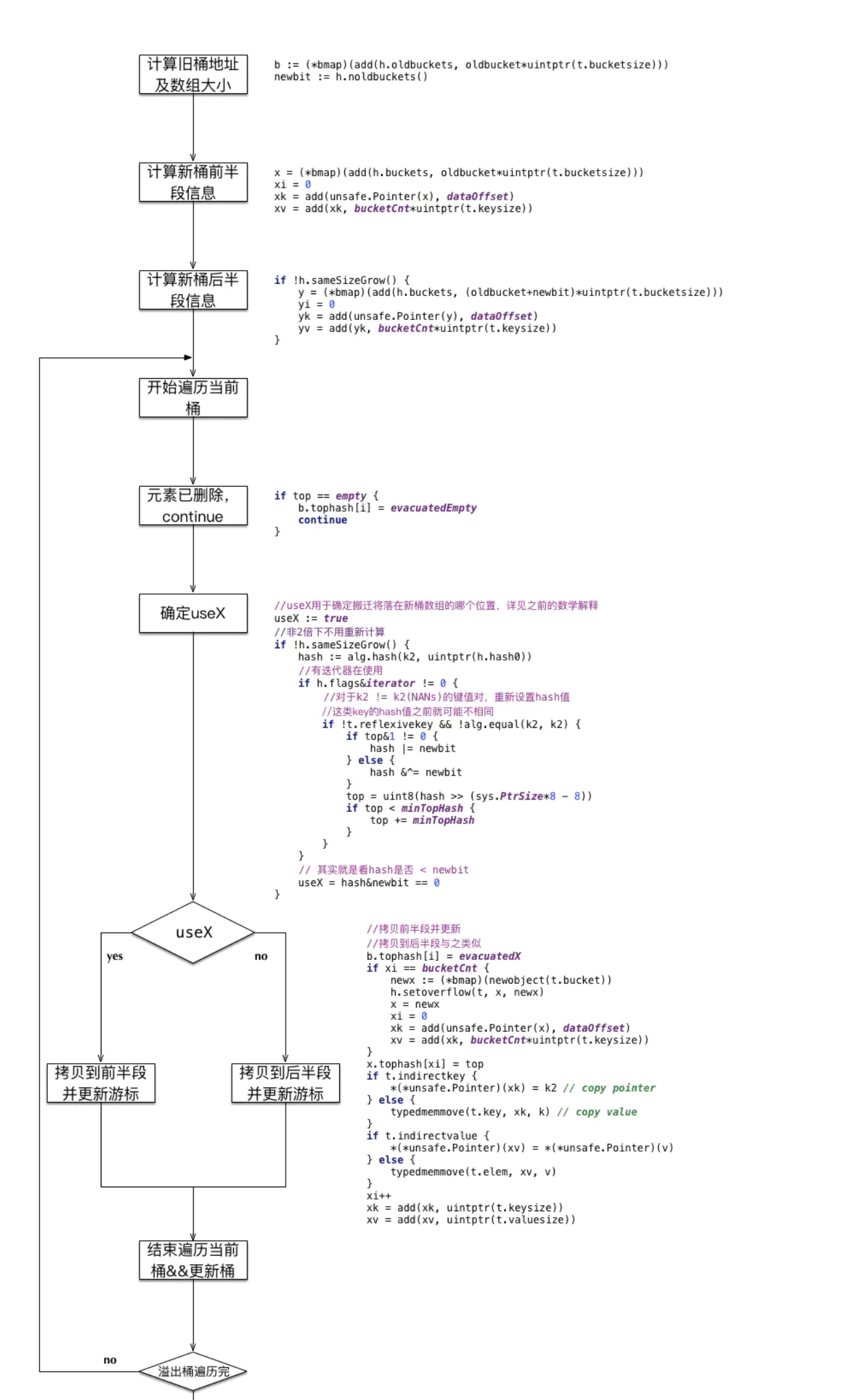

func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 定位老的 bucket 地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 结果是 2^B,如 B = 5,结果为32
newbit := h.noldbuckets()
// key 的哈希函数
alg := t.key.alg
// 如果 b 没有被搬迁过
if !evacuated(b) {
var (
// 表示bucket 移动的目标地址
x, y *bmap
// 指向 x,y 中的 key/val
xi, yi int
// 指向 x,y 中的 key
xk, yk unsafe.Pointer
// 指向 x,y 中的 value
xv, yv unsafe.Pointer
)
// 默认是等 size 扩容,前后 bucket 序号不变
// 使用 x 来进行搬迁
x = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
xi = 0
xk = add(unsafe.Pointer(x), dataOffset)
xv = add(xk, bucketCnt*uintptr(t.keysize))、
// 如果不是等 size 扩容,前后 bucket 序号有变
// 使用 y 来进行搬迁
if !h.sameSizeGrow() {
// y 代表的 bucket 序号增加了 2^B
y = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
yi = 0
yk = add(unsafe.Pointer(y), dataOffset)
yv = add(yk, bucketCnt*uintptr(t.keysize))
}
// 遍历所有的 bucket,包括 overflow buckets
// b 是老的 bucket 地址
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
// 遍历 bucket 中的所有 cell
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
// 当前 cell 的 top hash 值
top := b.tophash[i]
// 如果 cell 为空,即没有 key
if top == empty {
// 那就标志它被"搬迁"过
b.tophash[i] = evacuatedEmpty
// 继续下个 cell
continue
}
// 正常不会出现这种情况
// 未被搬迁的 cell 只可能是 empty 或是
// 正常的 top hash(大于 minTopHash)
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 如果 key 是指针,则解引用
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
// 默认使用 X,等量扩容
useX := true
// 如果不是等量扩容
if !h.sameSizeGrow() {
// 计算 hash 值,和 key 第一次写入时一样
hash := alg.hash(k2, uintptr(h.hash0))
// 如果有协程正在遍历 map
if h.flags&iterator != 0 {
// 如果出现 相同的 key 值,算出来的 hash 值不同
if !t.reflexivekey && !alg.equal(k2, k2) {
// 只有在 float 变量的 NaN() 情况下会出现
if top&1 != 0 {
// 第 B 位置 1
hash |= newbit
} else {
// 第 B 位置 0
hash &^= newbit
}
// 取高 8 位作为 top hash 值
top = uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
}
}
// 取决于新哈希值的 oldB+1 位是 0 还是 1
// 详细看后面的文章
useX = hash&newbit == 0
}
// 如果 key 搬到 X 部分
if useX {
// 标志老的 cell 的 top hash 值,表示搬移到 X 部分
b.tophash[i] = evacuatedX
// 如果 xi 等于 8,说明要溢出了
if xi == bucketCnt {
// 新建一个 bucket
newx := h.newoverflow(t, x)
x = newx
// xi 从 0 开始计数
xi = 0
// xk 表示 key 要移动到的位置
xk = add(unsafe.Pointer(x), dataOffset)
// xv 表示 value 要移动到的位置
xv = add(xk, bucketCnt*uintptr(t.keysize))
}
// 设置 top hash 值
x.tophash[xi] = top
// key 是指针
if t.indirectkey {
// 将原 key(是指针)复制到新位置
*(*unsafe.Pointer)(xk) = k2 // copy pointer
} else {
// 将原 key(是值)复制到新位置
typedmemmove(t.key, xk, k) // copy value
}
// value 是指针,操作同 key
if t.indirectvalue {
*(*unsafe.Pointer)(xv) = *(*unsafe.Pointer)(v)
} else {
typedmemmove(t.elem, xv, v)
}
// 定位到下一个 cell
xi++
xk = add(xk, uintptr(t.keysize))
xv = add(xv, uintptr(t.valuesize))
} else { // key 搬到 Y 部分,操作同 X 部分
// ……
// 省略了这部分,操作和 X 部分相同
}
}
}
// 如果没有协程在使用老的 buckets,就把老 buckets 清除掉,帮助gc
if h.flags&oldIterator == 0 {
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 只清除bucket 的 key,value 部分,保留 top hash 部分,指示搬迁状态
if t.bucket.kind&kindNoPointers == 0 {
memclrHasPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
} else {
memclrNoHeapPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
}
}
}
// 更新搬迁进度
// 如果此次搬迁的 bucket 等于当前进度
if oldbucket == h.nevacuate {
// 进度加 1
h.nevacuate = oldbucket + 1
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 尝试往后看 1024 个 bucket
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
// 寻找没有搬迁的 bucket
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 现在 h.nevacuate 之前的 bucket 都被搬迁完毕
// 所有的 buckets 搬迁完毕
if h.nevacuate == newbit {
// 清除老的 buckets
h.oldbuckets = nil
// 清除老的 overflow bucket
// 回忆一下:[0] 表示当前 overflow bucket
// [1] 表示 old overflow bucket
if h.extra != nil {
h.extra.overflow[1] = nil
}
// 清除正在扩容的标志位
h.flags &^= sameSizeGrow
}
}
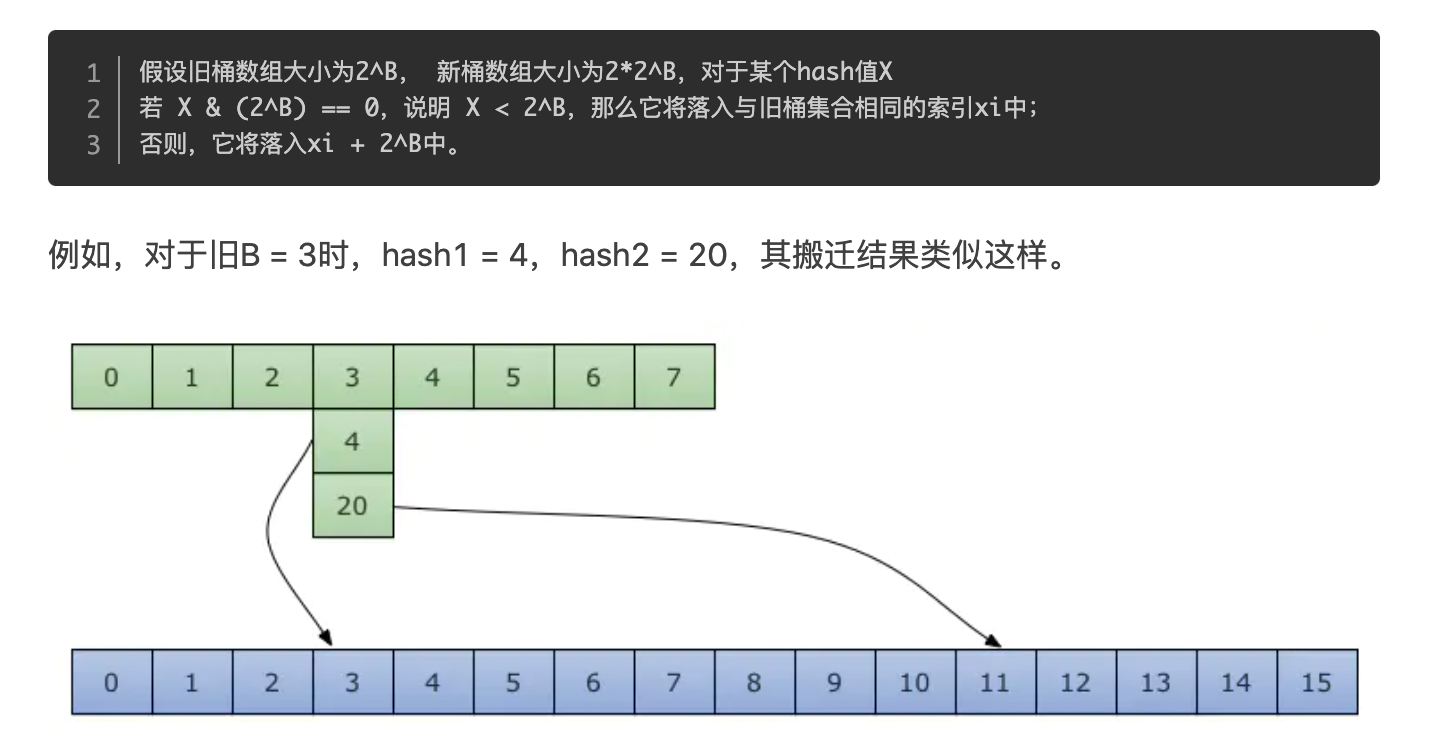
}源码里提到 X, Y part,其实就是我们说的如果是扩容到原来的 2 倍,桶的数量是原来的 2 倍,前一半桶被称为 X part,后一半桶被称为 Y part。一个 bucket 中的 key 可能会分裂落到 2 个桶,一个位于 X part,一个位于 Y part。所以在搬迁一个 cell 之前,需要知道这个 cell 中的 key 是落到哪个 Part。很简单,重新计算 cell 中 key 的 hash,并向前“多看”一位,决定落入哪个 Part,这个前面也说得很详细了。
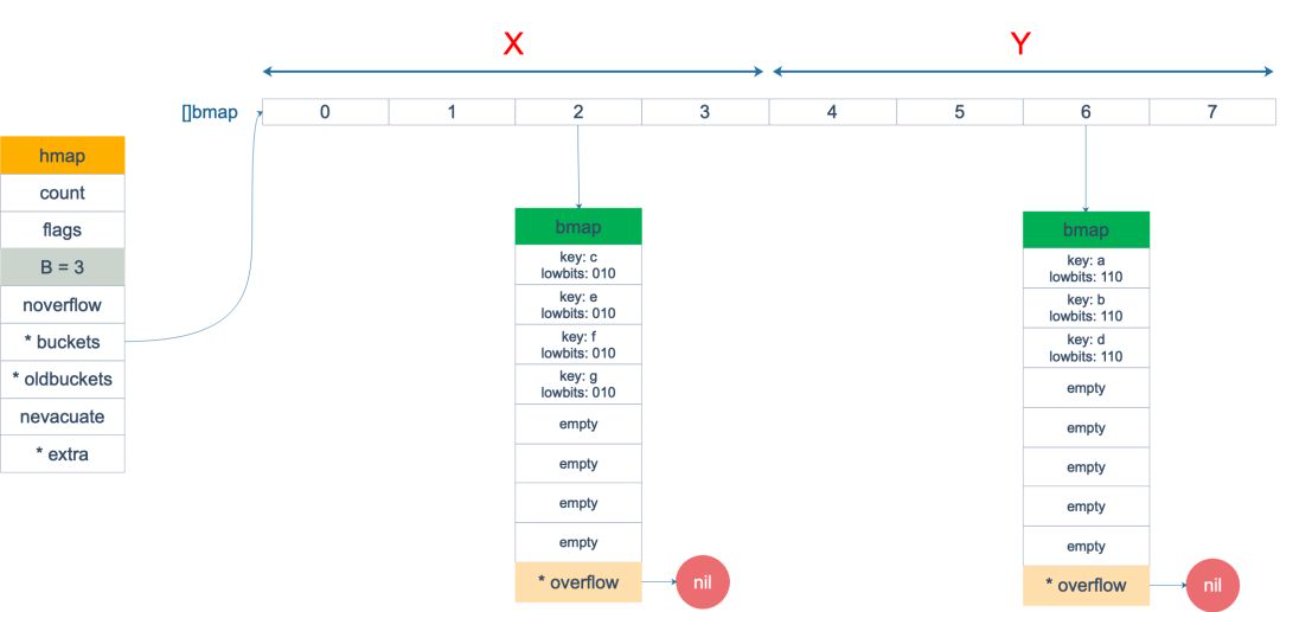
扩容前后的变化。
扩容前,B = 2,共有 4 个 buckets,lowbits 表示 hash 值的低位。假设我们不关注其他 buckets 情况,专注在 2 号 bucket。并且假设 overflow 太多,触发了等量扩容(对应于前面的条件 2)。

假设触发了 2 倍的扩容,那么扩容完成后,老 buckets 中的 key 分裂到了 2 个 新的 bucket。一个在 x part,一个在 y 的 part。依据是 hash 的 lowbits。新 map 中 0-3称为 x part, 4-7称为 y part。
minTopHash:
再来说一下minTopHash:
// 计算tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
//增加一个minTopHash(默认最小值为5)
if top < minTopHash {
top += minTopHash
}
return top
}当一个cell的tophash值小于minTopHash时,标志该cell的迁移状态。因为这个状态值是放在tophash数组里,为了和正常的哈希值区分开,会给key计算出来的哈希值一个增量:minTopHash,这样就能区分正常的tophash值和表示状态的哈希值。
emptyRest = 0 //这个单元格是空的,在更高的索引或溢出处不再有非空单元格
emptyOne = 1 //单元是空的
evacuatedX = 2 // key/elem有效. 实体已经被搬迁到新的buckt的前半部分
evacuatedY = 3 //同上,实体已经被搬迁到新的buckt的后半部分
evacuatedEmpty = 4 // 单元为空,以搬迁完成
minTopHash = 5 // 正常填充单元格的最小tophash源码中通过第一个tophash值来判断bucket是否搬迁完成:
func evacuated(b *bmap) bool {
//由于搬迁过程是一个循环过程,只要桶中第一个元素搬迁完成,后面肯定搬完了
h := b.tophash[0]
return h > emptyOne && h < minTopHash
}列表
在Go语言中,列表使用 container/list 包来实现,内部的实现原理是双链表,列表能够高效地进行任意位置的元素插入和删除操作。
初始化
- 通过 container/list 包的 New() 函数初始化 list
变量名 := list.New()- 通过 var 关键字声明初始化 list
var 变量名 list.List列表与切片和 map 不同的是,列表并没有具体元素类型的限制,因此,列表的元素可以是任意类型,这既带来了便利,也引来一些问题,例如给列表中放入了一个 interface{} 类型的值,取出值后,如果要将 interface{} 转换为其他类型将会发生宕机。
插入元素
双链表支持从队列前方或后方插入元素,分别对应的方法是 PushFront 和 PushBack。
l := list.New()
l.PushBack("fist")
l.PushFront(67)
for i := 1; i <= 10; i++ {
tmepList.PushBack(i)
fmt.Println(tmepList)
}
first := tmepList.PushFront(0)
fmt.Print(first)
tmepList.Remove(first)
fmt.Print(tmepList)
fmt.Print(tmepList.Front())
}双链表支持从队列前方或后方插入元素,分别对应的方法是 PushFront 和 PushBack。
这两个方法都会返回一个 list.Element 结构,如果在以后的使用中需要删除插入的元素,则只能通过 list.Element 配合 Remove() 方法进行删除,这种方法可以让删除更加效率化

从列表中删除元素
列表插入函数的返回值会提供一个 *list.Element 结构,这个结构记录着列表元素的值以及与其他节点之间的关系等信息,从列表中删除元素时,需要用到这个结构进行快速删除。
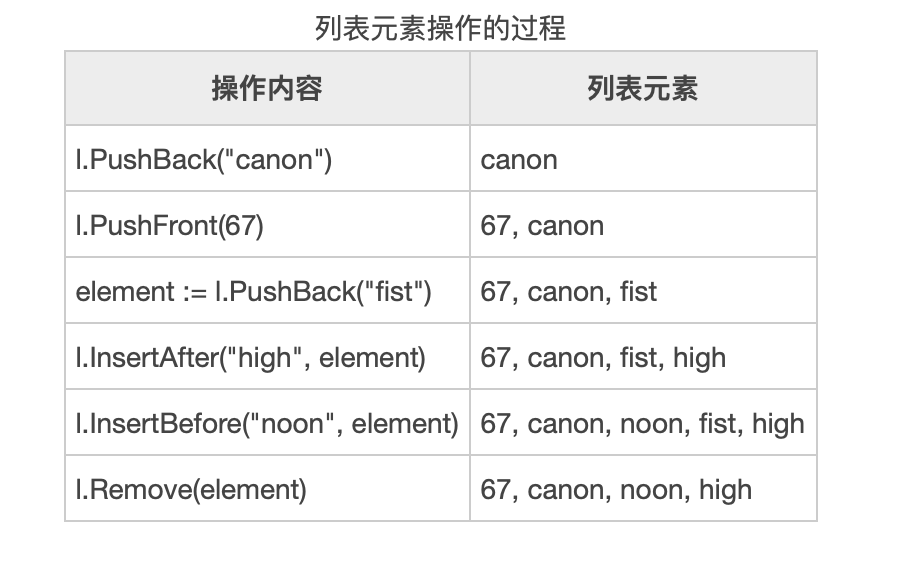
package main
import "container/list"
func main() {
l := list.New()
// 尾部添加
l.PushBack("canon")
// 头部添加
l.PushFront(67)
// 尾部添加后保存元素句柄
element := l.PushBack("fist")
// 在fist之后添加high
l.InsertAfter("high", element)
// 在fist之前添加noon
l.InsertBefore("noon", element)
// 使用
l.Remove(element)
}
遍历列表
l := list.New()
// 尾部添加
l.PushBack("canon")
// 头部添加
l.PushFront(67)
for i := l.Front(); i != nil; i = i.Next() {
fmt.Println(i.Value)
}容器遍历
主要通过for-range语法来进行遍历
//遍历数组
students3 := [3]int{}
for k, v := range students {
fmt.Println(k, v, " ")
}
//遍历切片
slicez := []int{1, 2, 3, 4, 5}
for k, v := range slicez {
//k为下标
fmt.Print(k, v, " ")
}
//遍历字典
map3 := map[int]string{
1:"ss",
2:"sss",
3:"dd",
}
for k, v := range map3 {
//k为键值,v为对应值
fmt.Print(k, v, " ")
}

