菊花细粒度识别——NTS-Net模型详解
Nts-Net(Navigator-Teacher-Scrutinizer Network,Nts-Net)应用于细粒度图像识别中。NTS-Net 将整张图像以及那些具有能强烈表示类别特征的区域所提取 的特征进行融合,有利于细粒度图像识别。所以,NTS-Net 进行识别的关键是如何定位最具有语义信息的局部区域。
如NTS-Net的名字所示,模型主要由三个网络部分组成:Navigator、Teacher、Scrutinizer网络。
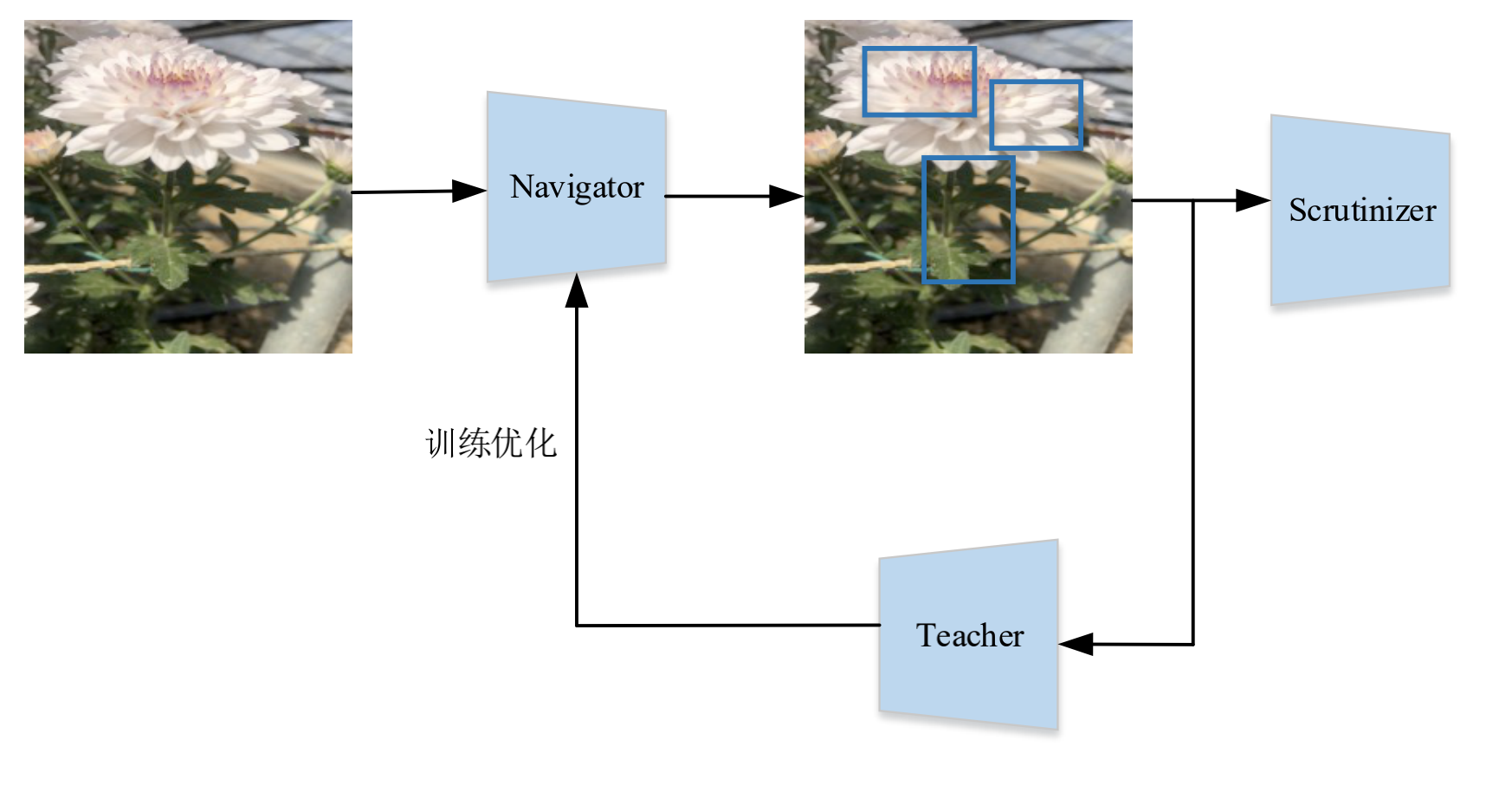
Navigator 的作用是让整个模型关注最具判别性的区域,Navigator 通过预测图像各个区域的信息量,提取出最具判别性的局部区域。当图像输入 Navigator 网络后,Navigator 网络会根据不同的比例和尺寸产生一系列矩形信息区域,并根据信息丰富度 排序。最后取其中信息度最大的 M 个区域,随后从完整的图像中映射对应的区域,把它们按照规定的尺寸,提取特征并送入到 Teacher 网络中,得到这 M 个区域的置信度并排序。局部区域的信息度反映的是对物体细粒度分类的表征能力,如果对 Teacher网络中的置信度进行排序,区域置信度的排序应与信息度的排序一致。所以,我们可以计算区域信息度和置信度的一致性的损失值,来对 Navigator 网络进行训练和优化。
下图是Teacher网络和Navigator网络自监督机制示意图:
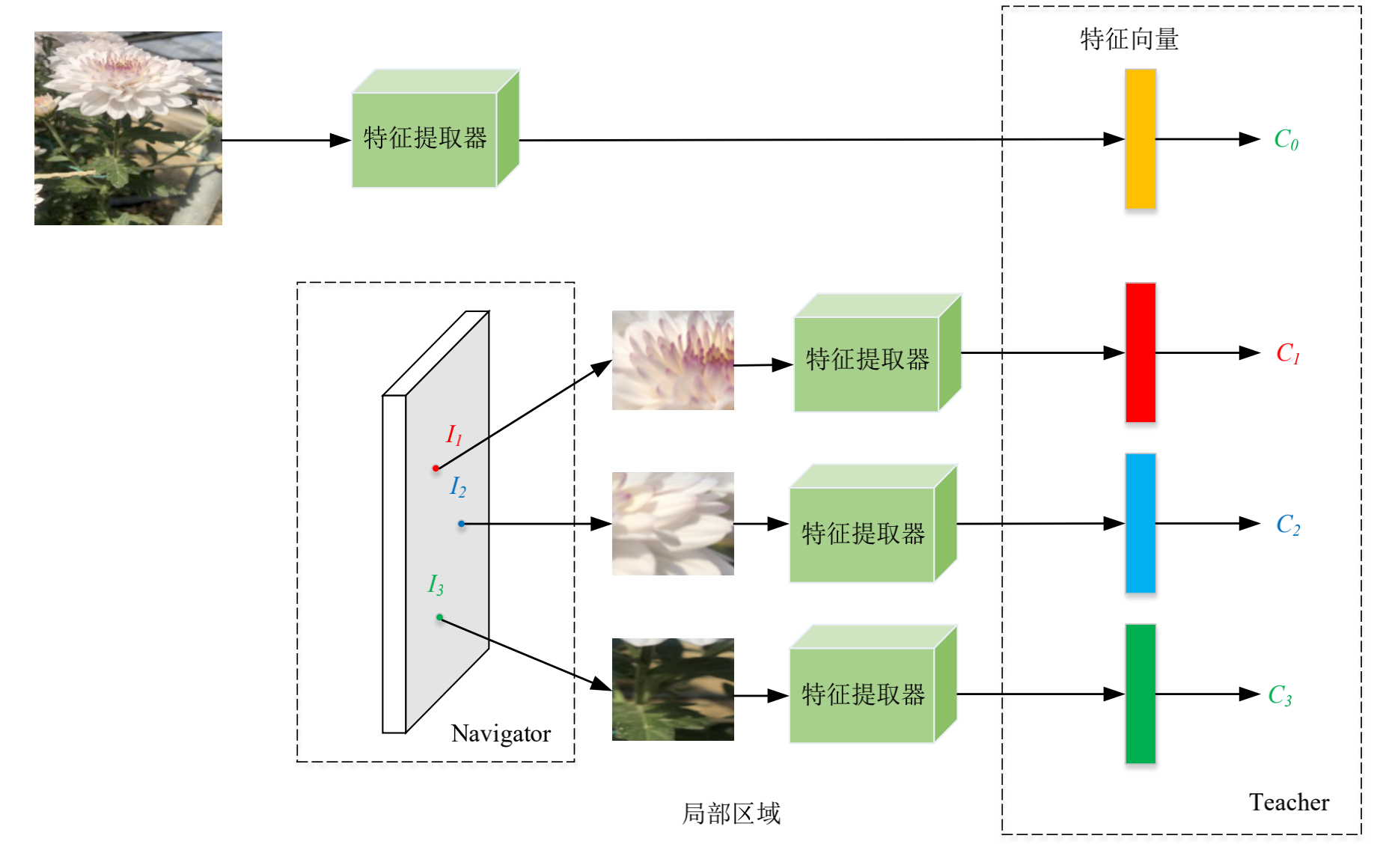
需要注意的是:局部区域经过特征提取网络提取特征后送入Teacher网络,经Teacher网络的全连接层得到菊花分类向量,再与标签进行交叉熵得到置信度。
Navigator网络将信息度最大的K个区域送往Scrutinizer网络,Scrutinizer网络提取这些局部区域的特征,然后将全局图像的特征和局部区域的特征拼接,最后送入全连接层分类。
下图是NTS-Net的检测过程:
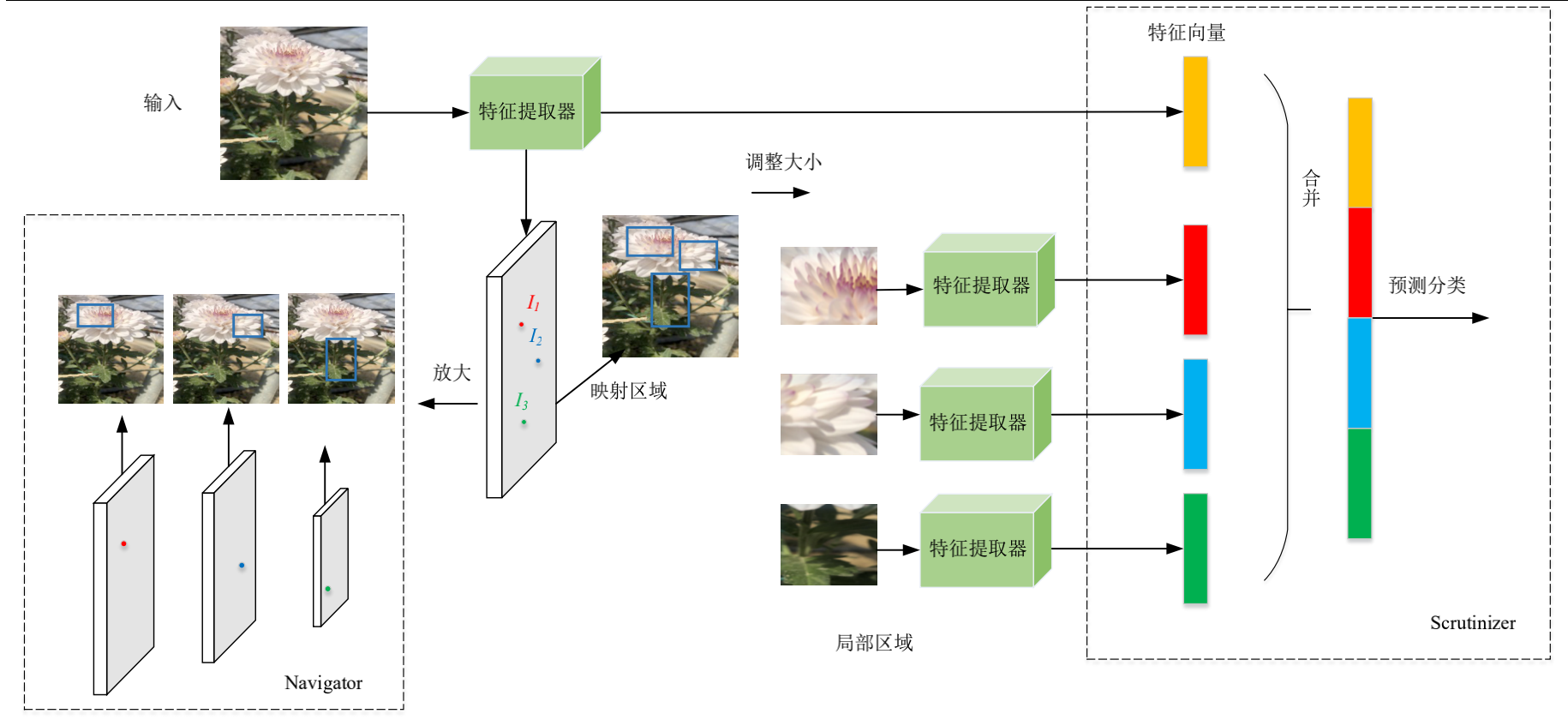
需要注意的是:局部区域是根据特征图与全局图像的映射关系上采样得到的。
核心代码理解:
NTS-Net的网络代码:model.py
from torch import nn
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from core import resnet
import numpy as np
from core.anchors import generate_default_anchor_maps, hard_nms
from config import CAT_NUM, PROPOSAL_NUM
num_class=115
class ProposalNet(nn.Module):
#不同尺寸的特征图要在不同大小的特征图上采样,。Navigator 网络在不同尺度的全局特征图上抠取不同尺寸的候选框的局部特征图。尺度为48、96、192的局部区域应该分别在大小为14
# ×14、7×7、4×4的特征图上抠取局部特征图
#ProposalNet得到不同尺度的特征图
def __init__(self):
super(ProposalNet, self).__init__()
self.down1 = nn.Conv2d(2048, 128, 3, 1, 1)
self.down2 = nn.Conv2d(128, 128, 3, 2, 1)
self.down3 = nn.Conv2d(128, 128, 3, 2, 1)
self.ReLU = nn.ReLU()
self.tidy1 = nn.Conv2d(128, 6, 1, 1, 0)
self.tidy2 = nn.Conv2d(128, 6, 1, 1, 0)
self.tidy3 = nn.Conv2d(128, 9, 1, 1, 0)
def forward(self, x):
batch_size = x.size(0)
d1 = self.ReLU(self.down1(x))
d2 = self.ReLU(self.down2(d1))
d3 = self.ReLU(self.down3(d2))
t1 = self.tidy1(d1).view(batch_size, -1)
t2 = self.tidy2(d2).view(batch_size, -1)
t3 = self.tidy3(d3).view(batch_size, -1)
return torch.cat((t1, t2, t3), dim=1)
class attention_net(nn.Module):
def __init__(self, topN=4):
super(attention_net, self).__init__()
self.pretrained_model = resnet.resnet50(pretrained=True)#特征提取网络、使用的是预训练网络RestNet-50
self.pretrained_model.avgpool = nn.AdaptiveAvgPool2d(1)
self.pretrained_model.fc = nn.Linear(512 * 4, num_class)
self.proposal_net = ProposalNet()
self.topN = topN #topN为送往Teacher网络的局部区域数量
self.concat_net = nn.Linear(2048 * (CAT_NUM + 1), num_class)#concat_net为Scrutinizer的全连接层,
# 输入的是拼接后局部特征向量和全局向量的特征向量 输出菊花各个种类的概率
self.partcls_net = nn.Linear(512 * 4, num_class)#Teacher网络中的全连接层,输入经特征提取网络的局部区域的特征图,输出菊花分类向量
_, edge_anchors, _ = generate_default_anchor_maps()
self.pad_side = 224
self.edge_anchors = (edge_anchors + 224).astype(np.int)#产生候选框
def forward(self, x):
resnet_out, rpn_feature, feature = self.pretrained_model(x)#第一步先得到全局图像的特征图
x_pad = F.pad(x, (self.pad_side, self.pad_side, self.pad_side, self.pad_side), mode='constant', value=0)
batch = x.size(0)
# we will reshape rpn to shape: batch * nb_anchor
rpn_score = self.proposal_net(rpn_feature.detach())#继续下采样得到不同尺寸的特征图
all_cdds = [
np.concatenate((x.reshape(-1, 1), self.edge_anchors.copy(), np.arange(0, len(x)).reshape(-1, 1)), axis=1)
for x in rpn_score.data.cpu().numpy()]
top_n_cdds = [hard_nms(x, topn=self.topN, iou_thresh=0.25) for x in all_cdds]#候选框极大值抑制,保留topN个候选框
top_n_cdds = np.array(top_n_cdds)
top_n_index = top_n_cdds[:, :, -1].astype(np.int)
top_n_index = torch.from_numpy(top_n_index).cuda()
top_n_index=top_n_index.long()
top_n_prob = torch.gather(rpn_score, dim=1, index=top_n_index)#top_n_prob为信息量
part_imgs = torch.zeros([batch, self.topN, 3, 224, 224]).cuda()
for i in range(batch):
for j in range(self.topN):
[y0, x0, y1, x1] = top_n_cdds[i][j, 1:5].astype(np.int)
part_imgs[i:i + 1, j] = F.interpolate(x_pad[i:i + 1, :, y0:y1, x0:x1], size=(224, 224), mode='bilinear',
align_corners=True)#上采样得到局部区域图像
part_imgs = part_imgs.view(batch * self.topN, 3, 224, 224)#part_imgs为所有局部区域图像
_, _, part_features = self.pretrained_model(part_imgs.detach())#part_feartures为所有局部区域图的特征图
part_feature = part_features.view(batch, self.topN, -1)#变换维度
part_feature = part_feature[:, :CAT_NUM, ...].contiguous()#根据信息量选择前几个
part_feature = part_feature.view(batch, -1)#转换维度
# concat_logits have the shape: B*200
concat_out = torch.cat([part_feature, feature], dim=1)#将局部特征图与全局特征图进行拼接
concat_logits = self.concat_net(concat_out)#concat_logits为全局和局部拼接后的特征分类向量
raw_logits = resnet_out
# part_logits have the shape: B*N*200
part_logits = self.partcls_net(part_features).view(batch, self.topN, -1)
#raw_logits为原图的特征向量,concat为原图和局部区域生成的特征分类向量,part_logits为所有局部区域的分类特征向量
return [raw_logits, concat_logits, part_logits, top_n_index, top_n_prob]
def list_loss(logits, targets):
#输入的是part_logits为局部区域的分类特征向量,targets为标签
#TODO 计算置信度
temp = F.log_softmax(logits, -1)#softmax,相当于将相加总和1。log再对每个进行log计算,方便计算交叉熵
loss = [-temp[i][targets[i].item()] for i in range(logits.size(0))]#计算交叉熵
return torch.stack(loss)#将loss中每个batch的loss拼接在一起
def ranking_loss(score, targets, proposal_num=PROPOSAL_NUM):
#输入score为top_n_prob,targets为part_loss
#计算信息度和置信度的排序是否一致、Navigator的损失函数
loss = Variable(torch.zeros(1).cuda())
batch_size = score.size(0)
for i in range(proposal_num):
targets_p = (targets > targets[:, i].unsqueeze(1)).type(torch.cuda.FloatTensor)
pivot = score[:, i].unsqueeze(1)
loss_p = (1 - pivot + score) * targets_p
loss_p = torch.sum(F.relu(loss_p))
loss += loss_p
return loss / batch_size
训练过程:train.py
trainset = data.MyDataset('./CUB200/new_train.txt', transform=transforms.Compose([
transforms.Resize(448),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(448),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
]))
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16,
shuffle=True, num_workers=0)
testset = data.MyDataset('./CUB200/test.txt', transform=transforms.Compose([
transforms.Resize(448),
transforms.CenterCrop(448),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
]))
testloader = torch.utils.data.DataLoader(testset, batch_size=16,
shuffle=False, num_workers=0)
# define model
net = model_cuda.attention_net(topN=PROPOSAL_NUM)
if resume:
ckpt = torch.load(resume)
net.load_state_dict(ckpt['net_state_dict'])
start_epoch = ckpt['epoch'] + 1
creterion = torch.nn.CrossEntropyLoss()
# define optimizers
raw_parameters = list(net.pretrained_model.parameters())
part_parameters = list(net.proposal_net.parameters())
concat_parameters = list(net.concat_net.parameters())
partcls_parameters = list(net.partcls_net.parameters())
raw_optimizer = torch.optim.SGD(raw_parameters, lr=LR, momentum=0.9, weight_decay=WD)
concat_optimizer = torch.optim.SGD(concat_parameters, lr=LR, momentum=0.9, weight_decay=WD)
part_optimizer = torch.optim.SGD(part_parameters, lr=LR, momentum=0.9, weight_decay=WD)
partcls_optimizer = torch.optim.SGD(partcls_parameters, lr=LR, momentum=0.9, weight_decay=WD)
schedulers = [MultiStepLR(raw_optimizer, milestones=[40, 80], gamma=0.1),
MultiStepLR(concat_optimizer, milestones=[40, 80], gamma=0.1),
MultiStepLR(part_optimizer, milestones=[40, 80], gamma=0.1),
MultiStepLR(partcls_optimizer, milestones=[40, 80], gamma=0.1)]
net = net.cuda()
net = DataParallel(net)
for epoch in range(start_epoch, 90):
# begin training
_print('--' * 50)
net.train()
for i, data in enumerate(trainloader):
img, label = data[0].cuda(), data[1].cuda()
niter = epoch * len(trainloader) + i
batch_size = img.size(0)
raw_optimizer.zero_grad()
part_optimizer.zero_grad()
concat_optimizer.zero_grad()
partcls_optimizer.zero_grad()
# raw_logits为原图的分类特征向量,concat为原图和局部区域生成的特征向量,part_logits为局部区域的分类特征向量
raw_logits, concat_logits, part_logits, _, top_n_prob = net(img)
#part_loss计算置信度
part_loss = model_cuda.list_loss(part_logits.view(batch_size * PROPOSAL_NUM, -1),
label.unsqueeze(1).repeat(1, PROPOSAL_NUM).view(-1)).view(batch_size, PROPOSAL_NUM)
#raw_loss是原图的特征分类向量与正确类别的交叉熵
raw_loss = creterion(raw_logits, label)
#是合并特征经全连接层输出的特征分类向量与正确类别的交叉熵
concat_loss = creterion(concat_logits, label)#Scrutinizer损失值
#top_n_prob为信息量,part_loss为置信度
rank_loss = model_cuda.ranking_loss(top_n_prob, part_loss)#navigator网络损失,比较信息度和置信度排序,计算损失值
#为为局部区域的分类特征向量与正确类别的交叉熵
partcls_loss = creterion(part_logits.view(batch_size * PROPOSAL_NUM, -1),
label.unsqueeze(1).repeat(1, PROPOSAL_NUM).view(-1))#局部区域的损失值,即Teacher网络=局部区域+整个图像
total_loss = raw_loss + rank_loss + concat_loss + partcls_loss
total_loss.backward()
raw_optimizer.step()
part_optimizer.step()
concat_optimizer.step()
partcls_optimizer.step()
writer1.add_scalars('Train_loss', {'train_loss': total_loss.data.item()}, niter)
# progress_bar(i, len(trainloader), 'train')
#调整学习率
for scheduler in schedulers:
scheduler.step()实验过程使用的预训练模型为RestNet-50,完整的代码可以去我的GitHub上NTS-Net上查看。


