细粒度识别模型-BCNN模型详解
Lin等提出的双线性卷积神经网络(Bilinear CNN,BCNN),BCNN 网络将两个特征提取网络提取的特征进行双线性融合操作,相比于一般的网络模型直接将特征送入全连接层,BCNN 多了双线性融合操作。
下图为B-CNN网络结构图
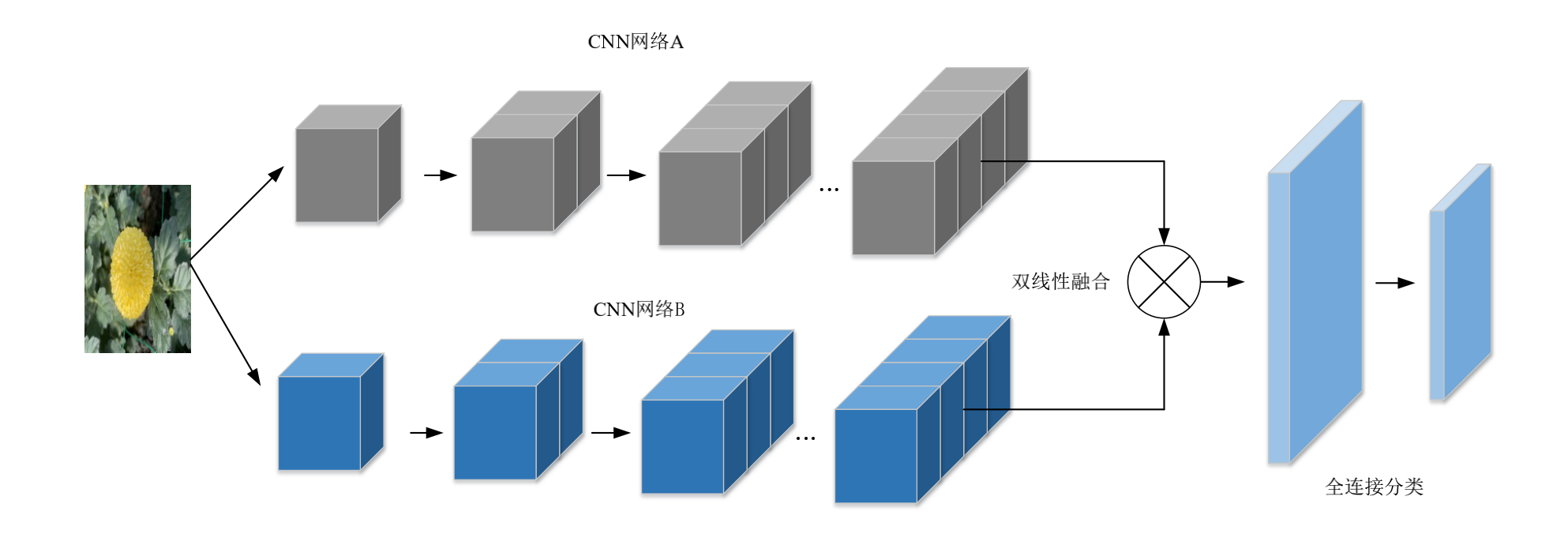
我在项目中使用的是对称的网络结构:
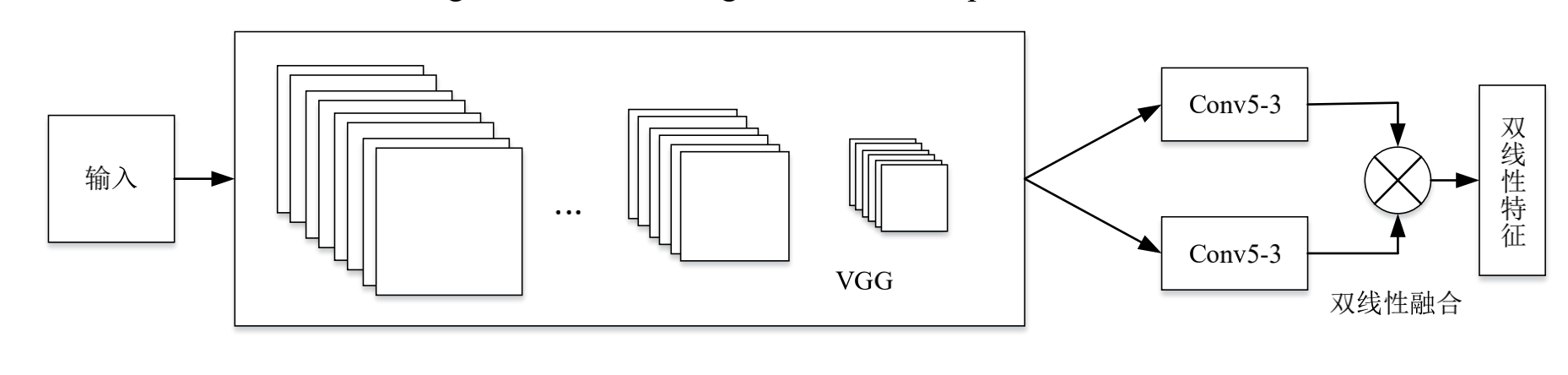
对于双线性融合操作可以这么理解:
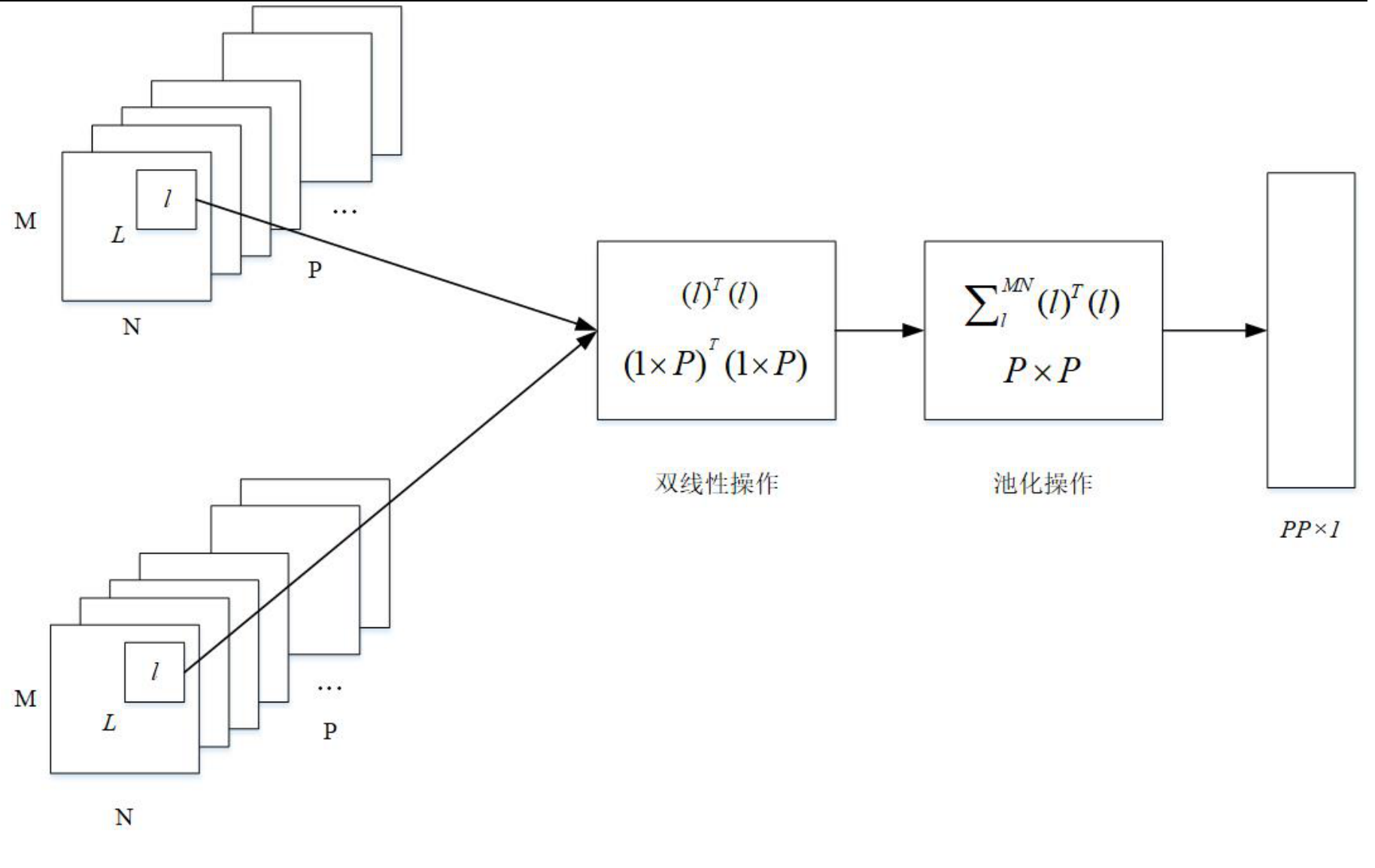
对于特征图的相同位置做外积操作,然后对所有位置的进行全局池化,即相加所有位置的外积结果,总共可以得到P*P个,即为双线性融合特征。
对得到的双线性融合特征需要做开方和归一化操作,最后送入全连接层分类,得到分类结果。
BCNN网络结构代码:bilinear_model.py
import torch
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
# vgg16 = torchvision.models.vgg16(pretrained=True)
# import os
# os.environ["CUDA_VISIBLE_DEVICES"] = "2"
num_class=115
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
# nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
# nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
# nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
# nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
self.classifiers = nn.Sequential(
nn.Linear(512 ** 2, num_class),
)
def forward(self, x):
x = self.features(x)
batch_size = x.size(0)
x = x.view(batch_size, 512, 28 ** 2) #将(batch_size,channel ,h,w)变为(batch_size,channel,h*w)维度的
x = (torch.bmm(x, torch.transpose(x, 1, 2)) / 28 ** 2)#torch.transpose(x, 1, 2))转置矩阵,将维度1和2的转置
# torch.bmm做外积 torch.bmm(a,b),tensor a 的size为(b,h,w),tensor b的size为(b,w,h),注意两个tensor的维度必须为3. 得到(batch_szie,512,512)
# / 28 ** 2平均池化
print(x.shape)
x=x.view(batch_size, -1)
# view(batch_size, -1)变成一维的张量
#normalize标准化,开方和归一化操作
x = torch.nn.functional.normalize(torch.sign(x) * torch.sqrt(torch.abs(x) + 1e-10))
# feature = feature.view(feature.size(0), -1)
x = self.classifiers(x)
return x
训练过程分为两步:
由于特征提取网络使用的是预训练的VGG-16,特征提取能力较强,所以可以只训练全连接层,对所有层的参数进行微调可以进一步提高准确率
第一步:固定特征提取网络参数,只训练全连接层
train_last.py
model = bilinear_model.Net()
print (model)
model.cuda()
pretrained = True
if pretrained:
pre_dic = torch.load("./vgg16-397923af.pth")
Low_rankmodel_dic = model.state_dict()
pre_dic = {k: v for k, v in pre_dic.items() if k in Low_rankmodel_dic}
Low_rankmodel_dic.update(pre_dic)
model.load_state_dict(Low_rankmodel_dic)
criterion = nn.CrossEntropyLoss()
#特征提取网络所有的输入都不需要保存梯度,那么输出的requires_grad会自动设置为False。既然没有了相关的梯度值,自然进行反向传播时会将这部分子图从计算中剔除
model.features.requires_grad = False
optimizer = optim.SGD([
{'params': model.classifiers.parameters(), 'lr': 1.0}], lr=1, momentum=0.9, weight_decay=1e-5)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(trainloader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {}'.format(
epoch, batch_idx * len(data), len(trainloader.dataset),
100. * batch_idx / len(trainloader), loss.data.item(),
optimizer.param_groups[0]['lr']))
###
###
###省略代码
torch.save(model.state_dict(), 'bcnn_lastlayer.pth')将第一步训练的参数保存,在第二步中加载
第二步:加载第一步的预训练参数,对所有层的参数进行微调
train_fintune.py
model = bilinear_model.Net()
model.cuda()
pretrained = True
if pretrained:
pre_dic = torch.load('bcnn_lastlayer.pth')
model.load_state_dict(pre_dic)
else:
for m in model.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-5)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(trainloader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {}'.format(
epoch, batch_idx * len(data), len(trainloader.dataset),
100. * batch_idx / len(trainloader), loss.data.item(),
optimizer.param_groups[0]['lr']))
###省略代码
torch.save(model.state_dict(), 'bcnn_alllayer.pth')完整代码可上Github上BCNN浏览,经过实验,微调参数确实比直接训练全连接层准确率高。


