ES查询
filter DSL和query DSL
filter DSL
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境
query DSL
在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”
如何验证匹配很好理解,如何计算相关度呢?ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。
精确查找
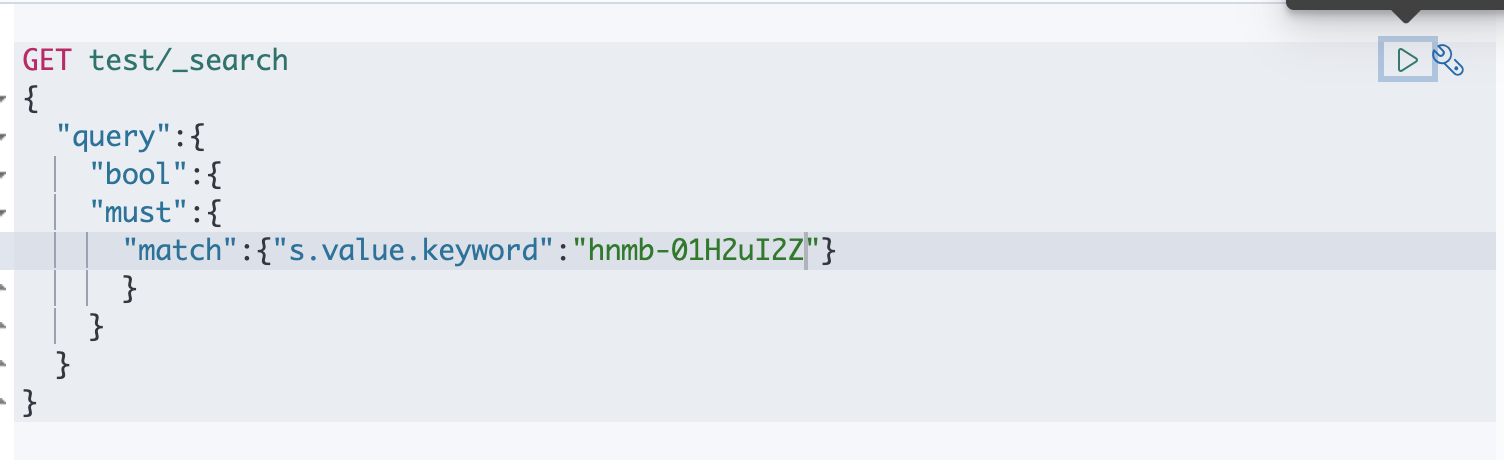
想要精确匹配一个字段,属性为keyword
term方法
term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇。主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串
term 必须对应 keyword的属性,不然查询不出,所谓keyword就是必须完全匹配,text可以模糊查询

如果仅用s.value 查询不出,因为s.value是text属性,
match
match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于term的精确搜索.
match 是queryDSL
term
term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇。主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串
terms
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
{
“terms”: {
“tag”: [ “search”, “full_text”, “nosql” ]
}
}range 过滤
ange过滤允许我们按照指定范围查找一批数据:
{
“range”: {
“age”: {
“gte”: 20,
“lt”: 30
}
}
}范围操作符包含:
gt :: 大于
gte:: 大于等于
lt :: 小于
lte:: 小于等于
exists 和 missing 过滤
exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件.这两个过滤只是针对已经查出一批数据来,但是想区分出某个字段是否存在的时候使用。
{
“exists”: {
“field”: “title”
}
}bool 过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:
{
“bool”: {
“must”: { “term”: { “folder”: “inbox” }},
“must_not”: { “term”: { “tag”: “spam” }},
“should”: [
{ “term”: { “starred”: true }},
{ “term”: { “unread”: true }}
]
}
}match_all 查询
{
“match_all”: {}
}
match 查询
match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配.它会在真正查询之前用分析器先分析match一下查询字符:
例如查询和”我的宝马多少马力”这个查询语句匹配的文档。
{
"query": {
"match": {
"content" : {
"query" : "我的宝马多少马力"
}
}
}
}上面的查询匹配就会进行分词,比如”宝马多少马力”会被分词为”宝马 多少 马力”, 所有有关”宝马 多少 马力”, 那么所有包含这三个词中的一个或多个的文档就会被搜索出来。
并且根据lucene的评分机制(TF/IDF)来进行评分。
multi_match 查询
如果我们希望两个字段进行匹配,其中一个字段有这个文档就满足的话,使用multi_match
{
"query": {
"multi_match": {
"query" : "我的宝马多少马力",
"fields" : ["title", "content"]
}
}
}match_phrase
比如上面一个例子,一个文档”我的保时捷马力不错”也会被搜索出来,那么想要精确匹配所有同时包含”宝马 多少 马力”的文档怎么做?就要使用 match_phrase 了
{
"query": {
"match_phrase": {
"content" : {
"query" : "我的宝马多少马力"
}
}
}
}完全匹配可能比较严,我们会希望有个可调节因子,少匹配一个也满足,那就需要使用到slop。
{
"query": {
"match_phrase": {
"content" : {
"query" : "我的宝马多少马力",
"slop" : 1
}
}
}
}通配符查询
wildcards 查询
查询能够匹配包含W1F 7HW和W2F 8HW的文档:
{
“query”: {
“wildcard”: {
“postcode”: “W?F*HW”
}
}
}
{
“query”: {
“wildcard”: {
“hostname”: “wxopen*”
}
}
}- regexp 查询
您只想匹配以W开头,紧跟着数字的邮政编码。使用regexp查询能够让你写下更复杂的模式:
{
“query”: {
“regexp”: {
“postcode”: “W[0-9].+”
}
}
}
所有以 wxopen 开头的正则
{
“query”: {
“regexp”: {
“hostname”: “wxopen.*”
}
}
}Nested查询
结构
PUT /blog_new
{
"mappings": {
"blog": {
"properties": {
"title": {
"type": "text"
},
"body": {
"type": "text"
},
"tags": {
"type": "keyword"
},
"published_on": {
"type": "keyword"
},
"comments": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"comment": {
"type": "text"
},
"age": {
"type": "short"
},
"rating": {
"type": "short"
},
"commented_on": {
"type": "text"
}
}
}
}
}
}
}
查询评论字段中评论姓名=William并且评论age=34的blog信息。
GET /blog_new/_search?pretty
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "William"
}
},
{
"match": {
"comments.age": 34
}
}
]
}
}
}
}
]
}
}
}ES创建索引

Post 方法,tt3为index,zlg为类型_type
POST /tt3/zlg
{
"mappings": {
"properties": {
"subj": {"type": "keyword"},
"height": {"type": "integer"},
"weight": {"type": "integer"},
"po":{
"type": "nested",
"properties":{
"pred":{"type":"keyword"},
"obj":{"type":"keyword"}
}
}
}
} }PUT方法
类型为_doc

PUT /tt1
{
"mappings": {
"properties": {
"subj": {"type": "keyword"},
"height": {"type": "integer"},
"weight": {"type": "integer"},
"po":{
"type": "nested",
"properties":{
"pred":{"type":"keyword"},
"obj":{"type":"keyword"}
}
}
}
} }ES添加文档(数据)
POST 或PUT

demo1为index,_doc为类型,3位id,id可以省略(省略就系统自动生成)
POST demo1/_doc/3
{
"subj": "qj",
"weight": 111,
"height": 12,
"po": [
{
"properties": {
"pred": "爱好",
"obj": "tv"
}
},
{
"properties": {
"pred": "性别",
"obj": "男"
}
}
]
}
批量插入需要id,命令行使用_bulk命令

/index/type/_bulk
跟上id,再跟里面的数据。
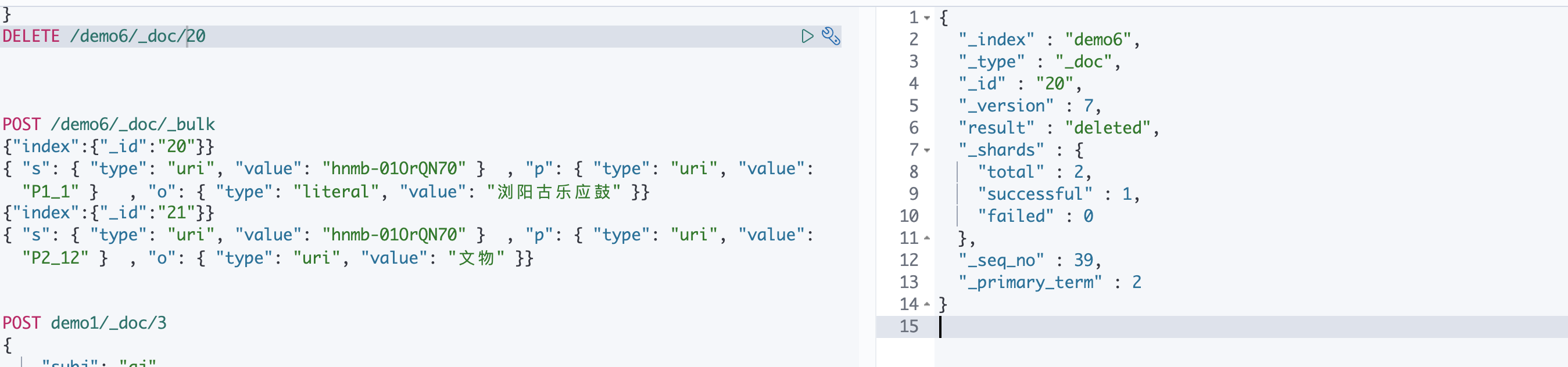
POST /demo6/_doc/_bulk
{"index":{"_id":"20"}}
{ "s": { "type": "uri", "value": "hnmb-01OrQN70" } , "p": { "type": "uri", "value": "P1_1" } , "o": { "type": "literal", "value": "浏阳古乐应鼓" }}
{"index":{"_id":"21"}}
{ "s": { "type": "uri", "value": "hnmb-01OrQN70" } , "p": { "type": "uri", "value": "P2_12" } , "o": { "type": "uri", "value": "文物" }}python 批量插入,读取每行的json数据,处理后构建插入的数据_source,然后自动生成id,组成action
import time
import os
from elasticsearch import Elasticsearch
from elasticsearch import helpers
def get_files_to_import(path):
f_list = os.listdir(path)
files_ = []
for i in f_list:
if os.path.splitext(i)[1] == '.json':
print(i)
files_.append(i)
return files_
# es = Elasticsearch('http://elastic:One4all4one@es-cn-mp90kb1bx0019j3cc.elasticsearch.aliyuncs.com:443')
if __name__ == '__main__':
# 默认不开启嗅探功能 es = Elasticsearch()
es = Elasticsearch()
# es = Elasticsearch(["***:9200", "***:9200"],
# sniff_on_start=True,
# sniff_on_connection_fail=True,
# sniffer_timeout=60,
# sniff_timeout=10
# )
actions = []
workspace = '/Users/zhulingang/Desktop/json'
files = get_files_to_import(workspace)
id_num, errors, success = 0, 0, 0
for json in files:
json = workspace + '/'+json
print(time.strftime('%y-%m-%d %H:%M:%S', time.localtime()))
this_file = open(json)
for line in this_file:
if line.endswith(',\n'): #读取的数据处理 假如每行最后有一个, 把逗号字符去除
line=line[:-2]
print(line)
action = {
"_index": "test",
"_type": "_doc",
"_id": id_num,
"_source": line
}
id_num += 1
# if id_num == 900000:
# print("++++++++++++++++++++++")
actions.append(action)
if len(actions) == 2000:
# print("======================")
err, suc = helpers.bulk(es, actions, chunk_size=2000, raise_on_error=False, stats_only=True)
errors += err
success += suc
del actions[0:len(actions)]
if len(actions) > 0:
suc, err = helpers.bulk(es, actions, chunk_size=2000, raise_on_error=False, stats_only=True)
errors += err
success += suc
del actions[0:len(actions)]
print("finish process file:%s" % json)
print(" down!\n success_num:\t %d" % success + " \n errors_num:\t %d" % errors)ES查看数据
GET 索引名/文档类型/文档id
GET /demo6/_doc/20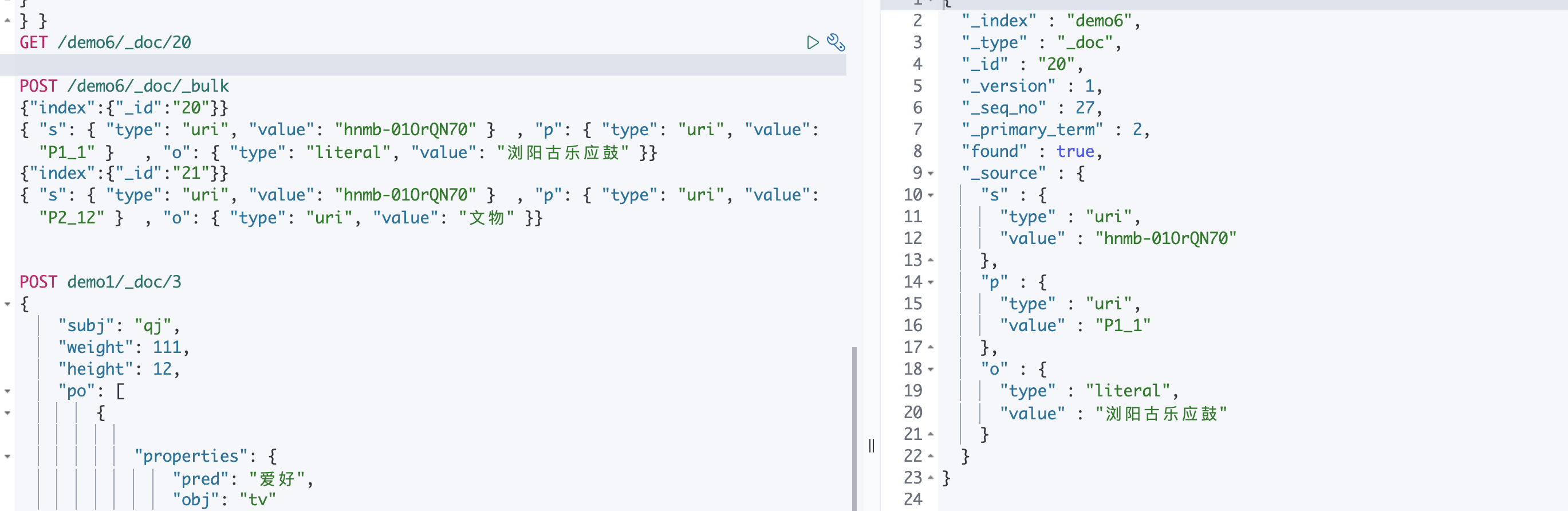
ES数据修改
put方式修改
put /索引名/文档类型/文档Id
{
"age":19,(修改的新值)
"content":"1"(修改的新值)
}
PUT /demo6/_doc/20
{
"s.type":"uri"
}要注意的是,当只修改一个属性的时候,如果只填这个属性,其他属性的值会消失。
如

s.value p.value 等属性消失。
Post 方式修改,当只修改一个属性,不会让其他属性消失。
POST /索引名/文档类型/文档Id/_update
{ "doc":{
"name":"张三的名字叫李四"
}
}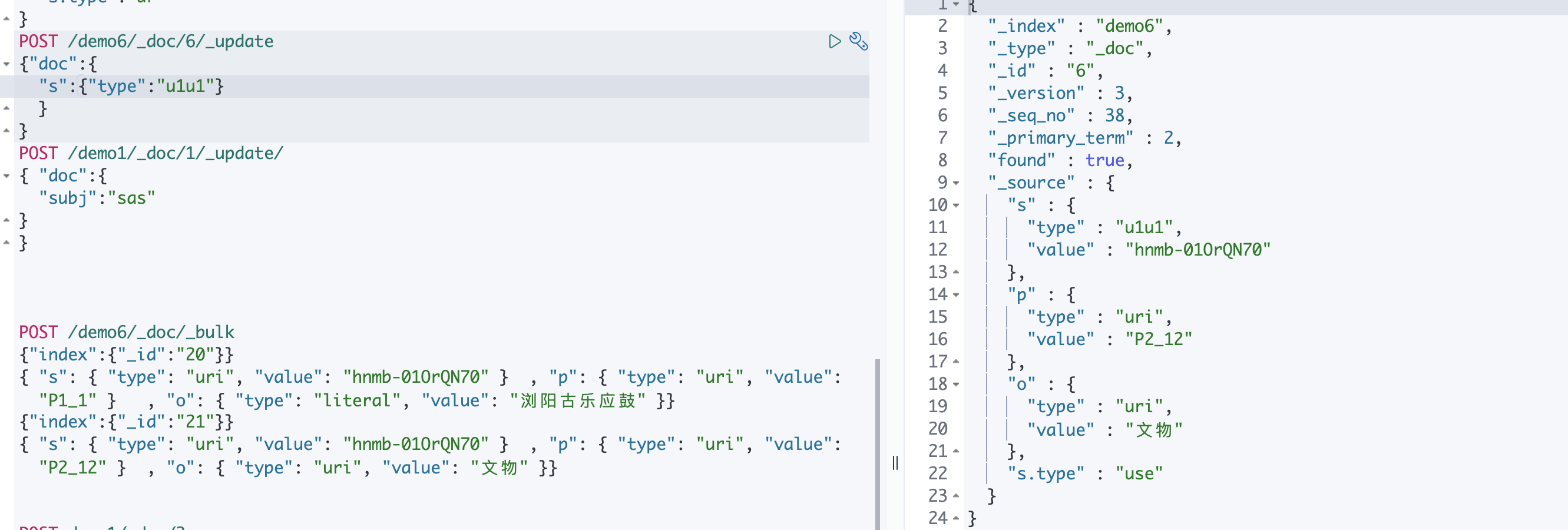
POST /demo6/_doc/6/_update
{"doc":{
"s":{"type":"u1u1"}
}
}
POST /demo1/_doc/1/_update/
{ "doc":{
"subj":"sas"
}
}假如属性值不存在 则会追加这个属性
删除文档&索引
删除索引:delete 索引名
删除文档:delete 索引名/文档类型/文档id